
Inventory and control of enterprise assets has been a mainstay at the number one spot for the most critical security control by the Center for Internet Security (CIS) for years. While most security professionals agree that having a good handle of your IT asset inventory is important, it’s surprising how frequently this control gets overlooked and deprioritized in enterprise environments. Let’s review the key aspects of a mature asset management program.
Discovery
You can’t secure it if you don’t know it exists.
There are a couple of technical methods that IT and security teams can use to discover new assets in their environment:
Agent-based discovery tools
With demilitarized zones (DMZ), multi-cloud deployments, and other modern approaches to security and availability, it’s becoming harder to find all company-owned and/or controlled assets. By scanning from your own endpoints you are likely to find rogue devices that either need your endpoint security software installed or warrant an investigation to find out what the device is doing on your network.
Fun fact: Several of the most popular EDR agents offer an agent-based discovery service:
- Network Device Discovery for Microsoft Defender for Endpoint
- CrowdStrike Falcon Discover
- Singularity Ranger for SentinelOne
- Palo Alto Cortex Xpanse Discovery
Agentless discovery tools
Passive and active scanning are two different approaches to discovering assets on a network. Each method has its own advantages and considerations, and they are often used in combination for a more comprehensive asset discovery strategy.
Passive scanning:
- Passive scanning involves observing and analyzing network traffic without actively sending requests or packets to devices.
- It relies on monitoring existing network communication to gather information about devices, services, and their configurations.
- Network traffic analyzers, intrusion detection systems (IDS), and tools like Zeek are examples of tools that can be used for passive scanning.
Active scanning:
- Active scanning involves actively sending requests or packets to devices on the network to elicit responses and gather information.
- It can include techniques like ping sweeps, port scans, and service enumeration.
- Nmap, Nessus, and OpenVAS are examples of tools commonly used for active scanning.
In many cases, organizations use a combination of passive and active scanning for more thorough asset discovery. This hybrid approach leverages the benefits of both methods while mitigating their respective limitations. Passive scanning provides continuous monitoring and real-time insights, while active scanning ensures a more complete and up-to-date inventory of assets on the network.
Ultimately, the choice between passive and active scanning depends on the specific goals, network characteristics, and security considerations of the organization.
For Red Canary customers with endpoints hosted in AWS, take a look at our Cloud Endpoint Discovery solution.
Deployment and naming convention standards
Organizations should commit to a standard naming convention for their endpoints. These names should be short and simple but meaningful. You can use a hostname to quickly determine where the endpoint is located and the types of assets with which it should be communicating. Here are some suggestions if you are considering adopting a new naming convention for your organization:
- Stick to alphanumeric characters (letters and numbers) to ensure compatibility with all applications and systems that may need to interact with your endpoints. Do not use special characters, as this may cause technical problems with applications and scripts. If legacy protocols like NetBIOS are a factor, be conscious of the limitations they may incur, such as a limited length of a hostname.
- Leverage the hostname to define where an asset is located. If your organization has multiple locations you can use an abbreviation to note its country or city of origin. You can use airport codes like “AUS” for Austin, “LHR” for London, or “AWS” for an endpoint hosted virtually in Amazon Web Services.
- Use the naming convention to define the endpoint’s functional role. This can be using abbreviations such as “DC” for domain controller, “FS” for file server, “DB” for database server, and “LT” for laptop.
- Use the naming convention to define the department or team its owner to which the endpoint is assigned. For example, you can use “FIN” for finance, “CS” for customer success, and “HR” for the people team.
Naming convention examples
| Hostname | Endpoint details |
|---|---|
| Hostname: BOS-SQL02 | Endpoint details : A Microsoft SQL server located in Boston |
| Hostname: AZR-DC01 | Endpoint details : A domain controller hosted in Microsoft Azure |
| Hostname: AWS-CTRX23 | Endpoint details : A Citrix virtual machine hosted in AWS |
| Hostname: LAX-FIN-LT75 | Endpoint details : A laptop assigned to a person in the finance department who reports into the Los Angeles area |
Asset tagging
Once your organization has committed to a standard naming convention, you’ll need to consider how your users and IT will physically identify each system. While this may be less important for assets bolted into a network rack in a datacenter, you’ll want to make it easy to identify laptops and desktops, especially when you are buying hundreds or even thousands of identical systems. Here are some suggestions:
- Use a label or sticker on each device assigned out to users.
- Make the hostname easy to identify. This will be incredibly helpful to your IT help desk when users are calling in and need to identify the computer that needs technical support.
- Consider using a barcode, QR code, or RFID that ties back to your central management solution.
- Consider using a tool, such as BgInfo (see screenshot below), that overlays the hostname on the user’s desktop after logging in. This will help make it apparent to users as well as administrators using remote management tools, if applicable.
Asset tracking
You need a technical solution that keeps track of all of your assets. While some organizations capture more data points than others, there are some standard things that should be documented in every organization:
- Device make
- Device model
- Device OEM serial number
- Hostname and/or asset tag
- Assigned user
- Assigned user’s team & department
- Physical location of asset
- Status
- Purchase date
- Warranty expiration date for physical devices/subscription expiration date for cloud-hosted virtual devices
Optional details to enrich your asset tracking:
- MAC address(es)
- IP address(es) for endpoints with static or reserved IPs
- Internal ticket numbers associated with the endpoint
- Manufacturer service records associated with the endpoint
- Contact details for the assigned end user
- Decommission/recycling records
- Non-endpoint devices, such as firewalls, switches, WAPs, printers, docking stations, and other peripherals
Asset lifecycle management
Consider the lifecycle of a computer in an enterprise environment:
- Procure the computer
- Unbox and physically set up the machine
- Image/onboard the computer with all appropriate software
- Provide the computer to the end user
- Normal end-user operations
- Maintenance
- Endpoint reimaged
- Endpoint becomes a spare, without being assigned to a user
- Reassignment to a new user
- Asset is with IT ops and ready for decommissioning
- Endpoint is recycled
If an organization keeps a laptop for five years, then that endpoint could easily be handed off to a dozen or so people. It’s important for an organization to keep records of every time an asset changes hands. For some organizations, this isn’t just best practice, but a regulatory requirement. ISO27001, FedRAMP, ITIL, and NIST SP 800-53 are a few examples of regulatory standards that require well documented change controls.
Policy and process
I’ve seen organizations successfully manage their IT asset inventory with inexpensive solutions and I’ve seen companies fail while paying for highly sophisticated SaaS products. To me, success is found in humans following a standard process. The tracking process and people behind a solution are more important than the platform used to carry it out. This mantra can be applied to a wide variety of technical processes in need of data consistency and accuracy. Here are some considerations when building a policy:
- Who is responsible for updating and maintaining the asset tracking system? Is it a person or a team?
- Are you applying the principle of least privilege when giving access to this system? The person(s) who can view it may get knowledge of sensitive information, such as terminations, issuance of new equipment, and reductions in force.
- How do employees inform the person or team in charge of this process that equipment has changed hands?
- Is there a need to periodically revalidate some or all of the asset database for accuracy and currency?
- Are there any regulatory requirements to report the status of asset tracking or any deficiencies that were identified?
- Where is the written procedural documentation located? Is it saved in a central location where it can be easily accessed by the employees who need to refer to it?
- How are physical endpoints recycled? What sort of coordination or collaboration is needed with your E-waste vendor? If your organization requires serialized certificates of destruction (COD) and proof of service (POS) for your hard drives, is this something that should be captured in your tracking system too?
The tracking process and people behind a solution are more important than the platform used to carry it out.
Collaboration between IT ops and security
How do security teams know when endpoints have been deployed or decommissioned? In many orgs, IT and security are segregated, with different sets of access and permissions. Security may only have access to EDR inventories, while IT has visibility into Active Directory and other network appliances. Here are some considerations:
- While IT ops may be responsible for managing the asset tracker, giving the security team permissions to view the IT asset inventory will allow security to run audits internally without as much IT involvement.
- Consider posture-checking solutions before devices are allowed access to corporate networks. You can enforce endpoints to have the company managed EDR agent installed before being granted access to a privileged network. This will reduce the number of unsecured assets that sit outside of the security team’s purview.
- The zero-trust security model suggests that users should authenticate to applications, not only networks. Posture checking can also be applied to applications and identities. Consider using solutions like Okta’s Device Assurance to ensure that devices are fully enrolled in all IT and security platforms before granting them access to sensitive systems. This will minimize the risk of unmonitored endpoint access to privileged data.
- Automate communications from the security team to IT ops when an endpoint is involved with an incident. If an endpoint is placed in quarantine and connections to the network are severed, it’s important to let IT know. The user may need a new computer issued immediately while the security team investigates threats on the user’s old system.
Asset management use cases within Red Canary
Although Red Canary is not an IT asset management solution, we have many features that help security professionals make sense of their inventory and automate common security tasks:
Auto-decommission endpoints that haven’t checked-in within a set amount of time
Customers who want to keep their Red Canary endpoint inventory clean may consider using an automation that will decommission endpoints that haven’t checked-in in a while. Administrators may want to consider setting different conditions for servers vs. workstations vs. endpoints that regularly come on/offline.

Use reporting tags on your critical assets
Many organizations want to make it easy for their security teams to identify and respond to critical assets. Red Canary customers can take advantage of the Reporting tags feature. Consider using these on tier 0 systems like domain controllers, Exchange servers, and key production servers. Reporting tags can be used as trigger conditions for Automate (Red Canary’s SOAR platform), filter criteria for inventory sorting, and display an identifier on threat timelines.
Alert when specific endpoints come online
If an endpoint involved with a threat or a larger security incident has gone offline, defenders will want to know when the endpoint comes back online so response actions can be taken. Consider how your organization would want to handle a stolen laptop; an automation trigger and playbook could be incredibly helpful to both IT ops and security teams.

Alert if critical asset has not checked-in
If the EDR sensor on a critical server has stopped checking in, organizations should be alerted right away so that they can troubleshoot. Defenders do not want to lose visibility on servers that are crucial to production. Use the following automation to get alerted when endpoints with a specific reporting tag haven’t checked-in in 24 hours.

Auto-inform IT teams when an endpoint they manage is involved with a security incident
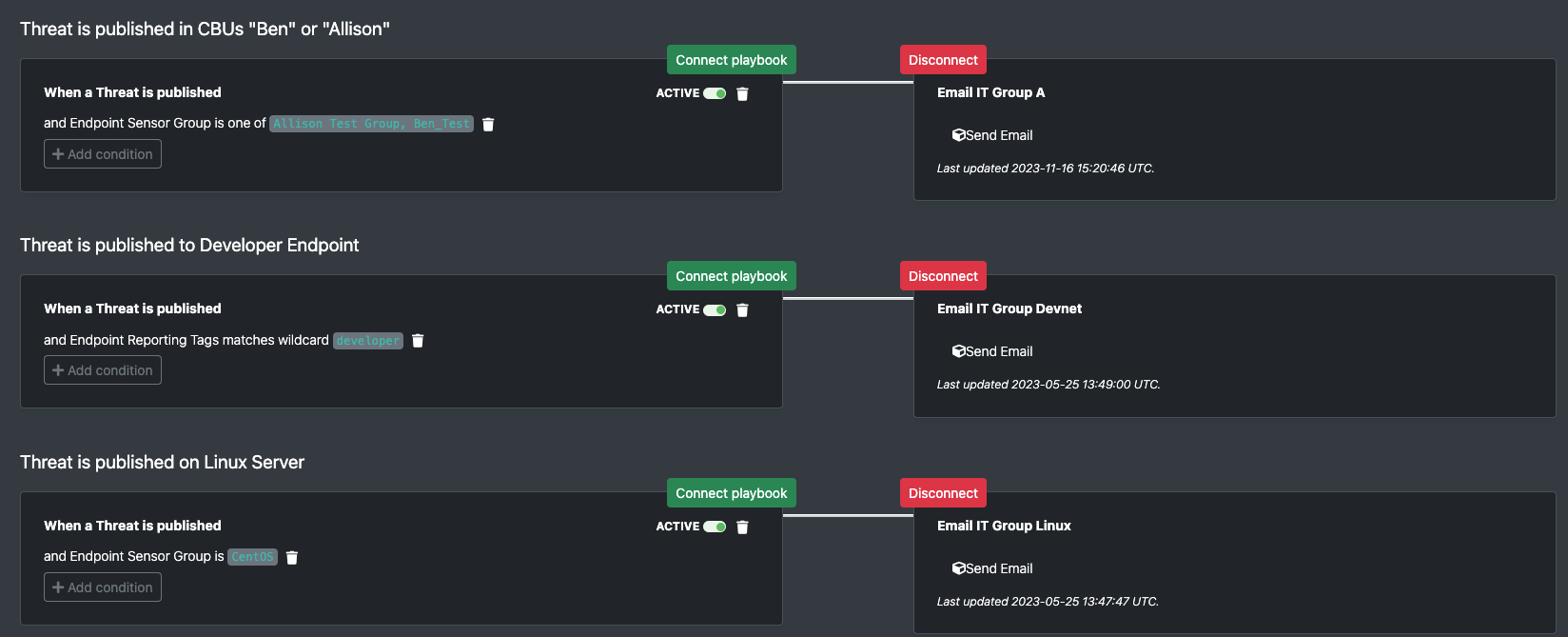
When an endpoint is involved in a security incident, IT should be notified for several reasons. After security defenders isolate the endpoint and the system can no longer access the network, how does IT know to not waste their time troubleshooting it? How does IT ops (or whoever owns the IT asset inventory) get notified that the end user’s system requires replacement or re-imaging? Notifying IT system owners that their endpoints are impacted by security incidents is a must that can be automated via the Red Canary platform:
Conclusion
In conclusion, organizations should understand the critical role of a mature endpoint-focused IT asset management program. I want to emphasize the importance of comprehensive asset discovery, standardized naming conventions, effective tagging and tracking, and well-documented change controls. While organizations should acknowledge the value of technical solutions, it’s arguably more important to focus on the success that hinges on humans following standard processes. This standard process should define how IT ops and security teams collaborate. And don’t forget, Red Canary can be used to augment and aid security professionals in inventory management and security task automation.
Related Articles
Shape shifting: How to wrangle unpredictable data at scale