
During a presentation at this year’s ATT&CKcon, I asserted that an alert means nothing without the proper context. After the presentation, we received loads of questions asking everything from “what is context?” to “how do we provide context to an alert?” In this post, I’ll show how the Red Canary CIRT applies various kinds of information to arrive at good findings, fast.

First, a refresher: what are alerts?
At its core, an alert is something that notifies you that an abnormal condition has occurred within a particular system. We consume alerts from lots of areas of our daily life. A simple example is an alert from a smoke detector. In this case, the abnormal condition for an alert is the presence of smoke. With any alert, contextual information is any form of data that will help you verify and take action on an alert. In the case of our smoke detector, contextual information includes visual observations, odors of smoke, or lots of heat. These data points help you determine that a fire is burning and you need to exit the building immediately.
In security tools, alerts follow the same scheme; they require criteria and abnormal conditions to go off. In addition, investigators require contextual information so that they can verify and take action. This information is what leads us to say “alerts without context mean nothing.”
Divergent vs. convergent thinking
When triaging alerts, investigators (analysts or otherwise) must get a little creative. Chris Sanders and Stef Rand presented some awesome research around this concept at Security Onion Con 2019. To top it off, they published a paper documenting a mental model showing the application of creativity in investigations. Their research shows that analysts faced with high-stakes investigations typically use forms of divergent and convergent thinking to enumerate and choose leads to follow when triaging an alert. Convergent thinking is linear and logical, focused on a single outcome, while divergent thinking is web-like, focused on the relationships between multiple ideas. An analyst can use divergent thinking to consider all the possible ways to investigate an alert and then converge on one single path to move forward.
As we discuss the concept of adding context to alerts, contextual information will be any data that helps move analysts from the divergent thought process through convergence on one path.
According to Sanders and Rand’s criteria, the Red Canary CIRT conducts high-stakes investigations every day, since each alert (or event, in our parlance) is subject to peer review. Because of this, we’ve reaped a lot of benefits from using context to help focus this thought process, before we even knew what to call it!
A systematic investigation process
When training detection engineers (DE), we like to start them out with a systematic process for investigations. This helps newer engineers hone their skills and ensure they can step through a portion of the process before asking for help from senior analysts. First, the DE can gain situational awareness before analysis. This is done by reading through customer notes and evaluating data presented to them in our custom event block. The DE can look through previous malicious activity from this host and conduct their investigation to triage the current event. During analysis, the DE begins to investigate using a timeline and data presented from an EDR platform. This is when divergent thinking comes into play.
Using divergent thinking, the DE enumerates possible leads based on the sum of the facts presented. Depending on the event received, they may need to investigate network connections, file modifications, or other data points. In some investigations, a DE may need to find activity on multiple hosts to confirm that lateral movement occurred. After sorting the choices, the DE converges on one best path to move forward until every lead is explored, landing on an educated decision to triage the event.
Guiding divergent thinking
An approach that has worked well for us is to provide a wealth of knowledge at our fingertips to help enumerate all the possible leads in a short amount of time. We’ve worked for years to improve our interfaces, and our current view to triage events looks similar to this:
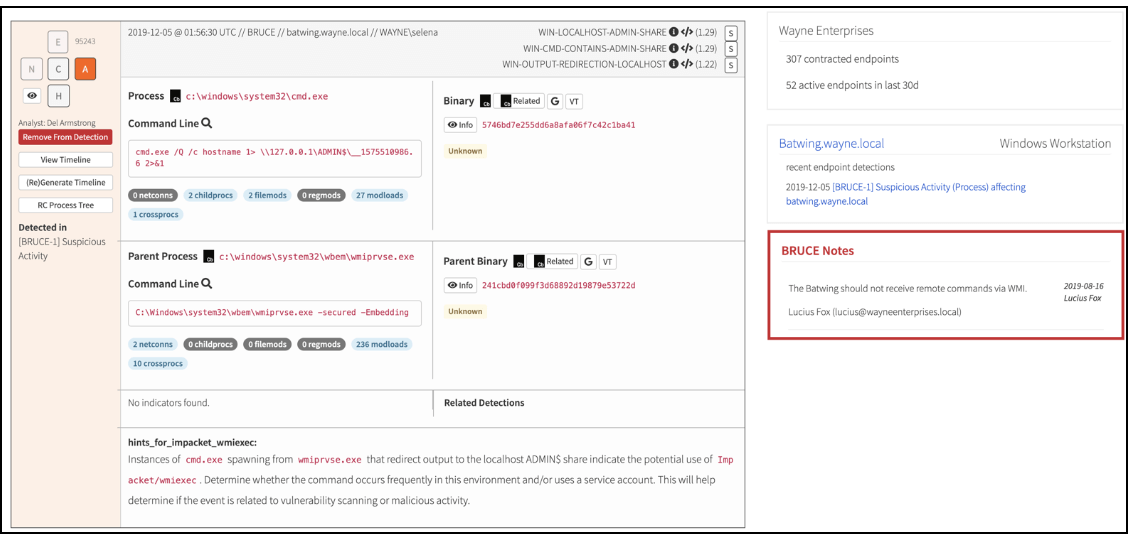
Along the top left, we observe details like the time the process started, the relevant host, and the relevant user in a customer environment.
Further to the right is a list of detector criteria that caused this event to generate. In this case, three of our detectors were matched by this single process. In our workflow, a single detector can cause event generation but it’s always interesting to see events with multiple criteria. Alongside each detector criteria is an impact score. This gives us a measure of how often the detector criteria leads to a suspicious or malicious detection. It’s weighted by the amount of time an event waits for evaluation so we can use the impact scores to determine the priority of event triage. Events with higher impact scores tend to reliably find evil behaviors, so we make those the priority over some more ambiguous events.
Under those initial pieces of data is some self-explanatory information. We make process paths and command lines immediately available for inspection. In the case of Base64-encoded PowerShell command lines, we even attempt to remove encoding. Next to those details we include a few buttons to accelerate our ability to view binary information in Carbon Black Response binary stores, Google a process name, or search for an MD5 hash in VirusTotal.
On the far right we make basic customer information available to a DE, such as customer name and size. Immediately under that information are recent endpoint detections and customer notes to help influence discretion during analysis. At the bottom of the event block we include information for first-party intelligence from previous analysis. If any indicators of compromise (IOC) are found for a process, the hashes, IP addresses, domains, or filenames will appear in the indicator field. If applicable, a DE will also have a list of previous detections containing that IOC to determine its significance in this event. Below that, we can associate hints from the CIRT Intelligence team to help guide analysis and let DEs know what kind of tools or malware families may be present.
But wait, there’s more.
If you notice the buttons beside the detector name at the top, a simple mouseover will display the exact detector criteria and documentation to help a DE triage the event.
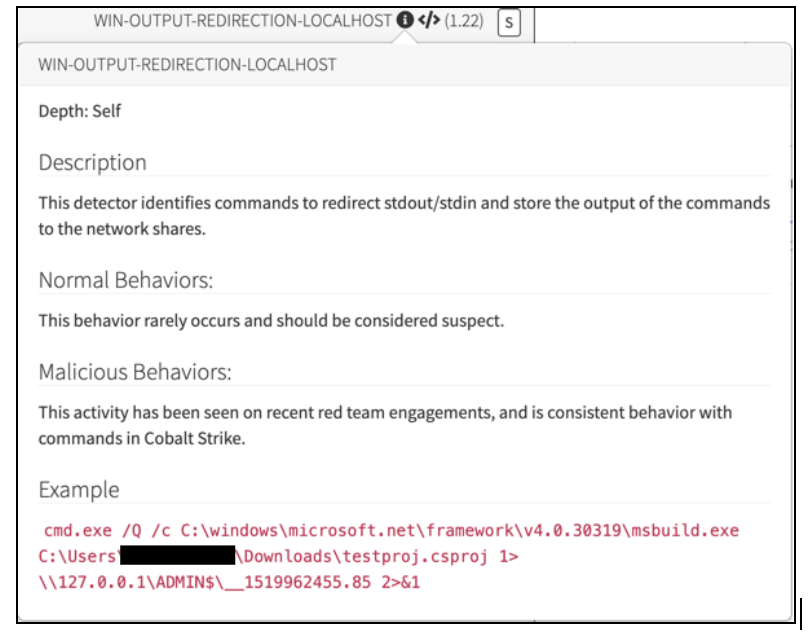
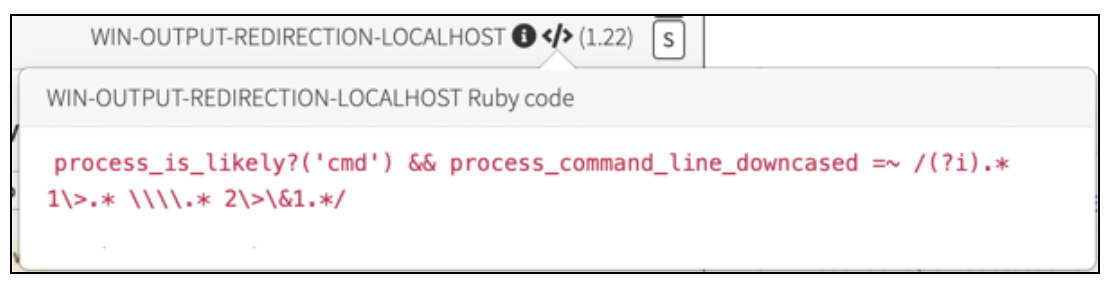
Once a DE reviews this information, they can view a timeline of process activity. For the sake of brevity, I’ll show a brief portion of a timeline below:
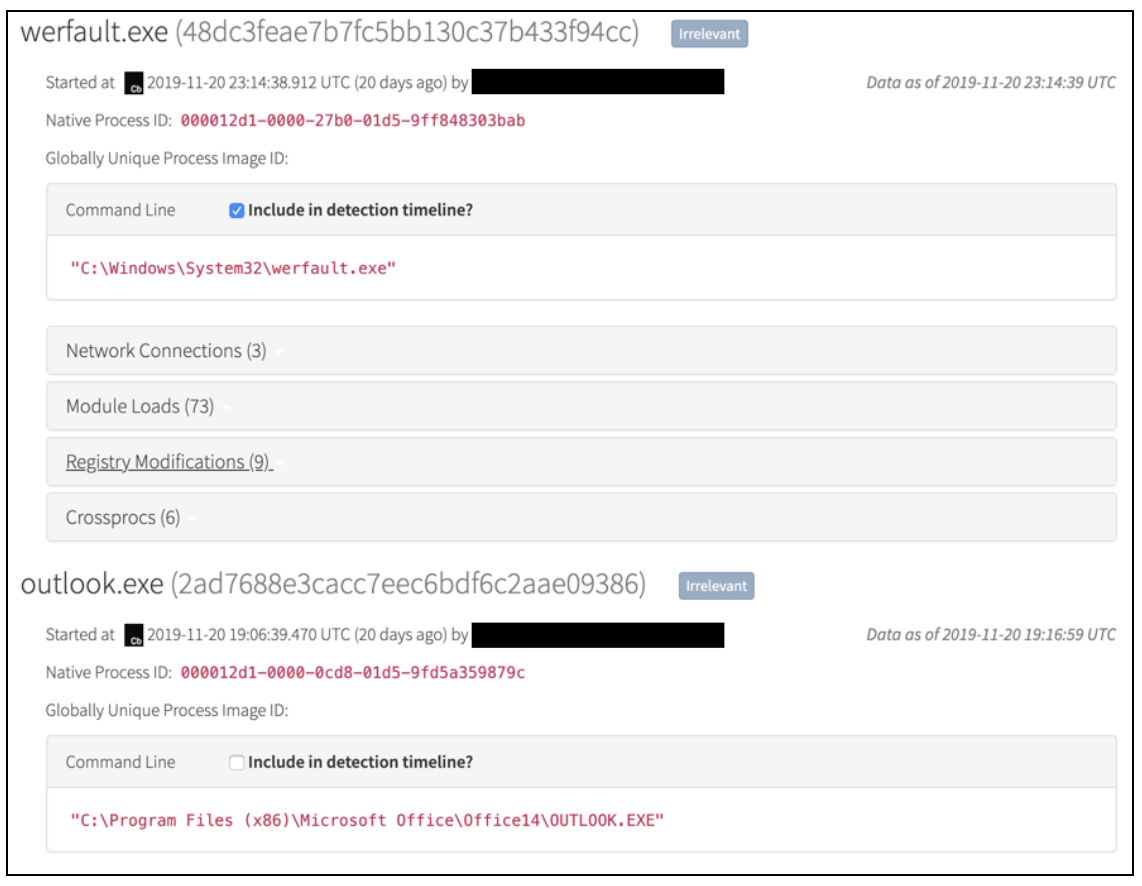
We observe file modifications and hashes of special file types calculated by the EDR product. For network connections we observe domains, IP addresses, and reverse domain lookups. For Windows Registry modifications, we observe key and value names. With select EDR products, we may also observe Registry values. Finally, we observe select cross-process communications and injections, depending on the capabilities of the EDR product used. If something isn’t clear, the DE can also access the EDR product’s console to chase additional leads. If a DE wants to perform temporal analysis of other processes that occurred around a specific process on the timeline, they can click the EDR logo next to a timestamp and pivot into the EDR platform to investigate.
With all of this information, the DE team can choose a lead to pursue. Maybe it will be most helpful to find other hosts involved in lateral movement immediately. Maybe the best path is to determine the reputation of an executing process suspected of credential theft. All of these data points steer analysis to converge on a single best path, and the sooner you can move from divergent to convergent thinking, the quicker the investigation.
Finding your context
We include this contextual information because it has proved helpful to our organization. Red Canary is a managed endpoint detection and response service, so the best context for us to make judgements combines EDR data with alert criteria and customer-specific information. Your organization will likely need different data points to make educated judgements for alert triage.
The best way to determine what data you need is to ask your CIRT personnel. The people triaging alerts have a clear understanding of what data they need for situational awareness and for investigative leads. Take input from those personnel and look for ways to fit data into alerts or the interfaces you use to triage them in unobtrusive ways. The best part of customizable tools and interfaces is that you can incrementally improve your experience, trying new things and discarding the things that don’t work for you.
Once you’ve met the needs of your CIRT, you can begin to focus on goals to improve the quality of the investigative process at a higher level. Try conducting experiments to determine which data points in contextual information lead to more favorable metrics. For example, do network investigations move faster when analysts don’t need to perform DNS lookups manually? If this is the case in your environment, try to automatically include those lookups for better metrics. Little changes can have a big impact on your organization, from morale and capabilities to metrics and process improvements.
Related Articles
Train, triage, repeat: The AI agent changing how we fight phishing
The dual-use dilemma: Rethinking detection for remote access tool abuse
The dual-use dilemma: Rethinking detection for remote access tool abuse
Investigating suspicious AI workflows in Microsoft Entra Agent ID: Assistive agents