
Endpoint detection and response (EDR) has revolutionized the way organizations secure their endpoints. In contrast to previous detection tools, EDR solutions provide real-time monitoring and analysis of endpoint activity, enabling organizations to detect and respond to security threats more quickly and effectively. By collecting telemetry from endpoints, EDR solutions can identify and provide detailed information about suspicious behavior to help organizations respond appropriately. However, as adversaries become more sophisticated and the technology landscape evolves, modern EDR solutions face many challenges. One such challenge is the heavy use of containerization on production systems.
Containers can be created and destroyed quickly. Their ephemerality presents a challenge for anyone trying to maintain visibility via an EDR solution. Containers run in their own isolated environments, which can obscure EDR detection capabilities. Additionally, containers may be deployed across multiple hosts, making it difficult for EDR solutions to track container activity effectively.
In this blog post, we’ll discuss the benefits of EDR, some of the current challenges facing EDR solutions, and how the rise of containerization has made it even more difficult to monitor endpoint activity. We hope to shed some light on how defenders can more effectively monitor container-based environments.
Introduction to containers
NOTE: This article treats containers generally and assumes a fairly standard configuration. Depending on the container engine and how it’s configured, the behavior of containers may differ slightly from what’s described here.
To start, we need to understand some fundamentals about containers. Containers are a type of virtualization technology that enables multiple applications to run on the same operating system instance, each in its own isolated environment. Unlike virtual machines, which require a separate operating system instance for each application, containers share the same operating system kernel, making them more lightweight and efficient. Containers also enable developers to package their applications and dependencies into a single, portable unit that can run anywhere, from a developer’s laptop to a public cloud.
To set the stage for what we will discuss next, we need to establish that the Linux kernel has no concept of a container as we generally think of them. Rather, the technology that gives rise to containers is a combination of various kernel features with a sprinkle of higher-level management software on top. In this blog, we will focus mostly on the kernel support required to create containers. Let’s dive in!
Namespaces
Linux namespaces are used to provide isolation of various system resources, such as network, process, user, mount points, and IPC (inter-process communication). Each container has its own set of namespaces that limit its visibility and access to the host system’s resources. This means that processes running inside a container can’t see or interact with processes outside of it, even if they are running on the same host.
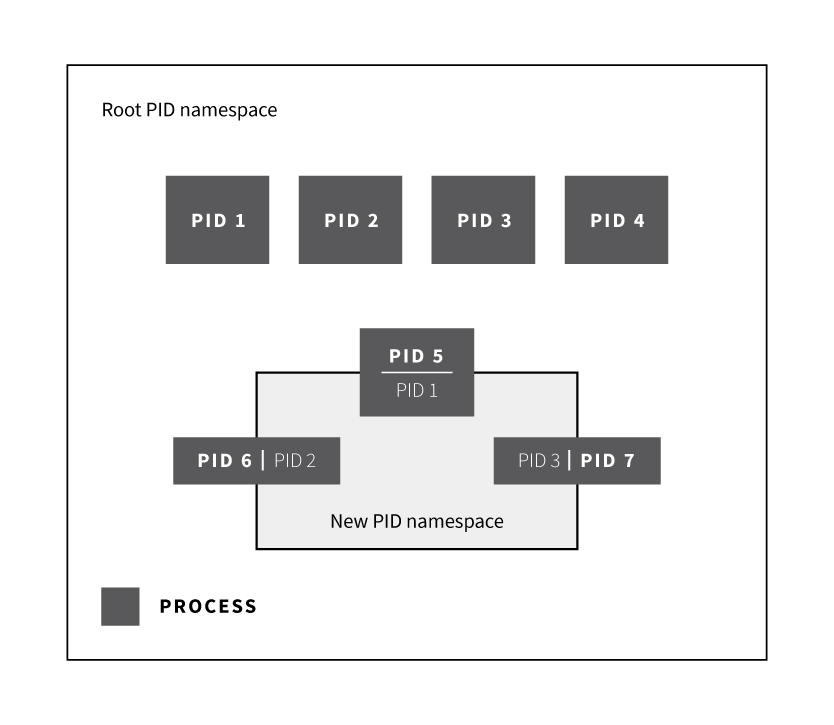
The diagram below illustrates how processes that are in a new process ID (PID) namespace interact with the rest of the system. There is a root PID namespace that always exists. Then, processes that are added to a new PID namespace get a second PID that is only relevant to the new PID namespace. For example, the process with PID 5 in the root namespace also is PID 1 in the new PID namespace.
Control groups (cgroups)
Cgroups are used to manage and allocate system resources such as CPU, memory, disk I/O, and network bandwidth to containers. With cgroups, you can specify how much of each resource a container can use, which prevents containers from overusing resources and impacting other containers or the host system.
For a deep dive on how namespaces and cgroups are used by containers, check out this great talk given at DockerCon EU back in 2015.
Filesystem isolation
Containers generally use pivot_root to create a container-specific filesystem that is logically isolated from the host’s filesystem. This means that each container has its own root directory, which is isolated from the host system’s root directory. Containers can access only their own filesystem and can’t modify the host system’s files or directories.
NOTE: This is generally true but depending on how the container was configured, it may share some of the filesystem with the host.
For a deep dive on the technology behind file system isolation, check out this talk from DockerCon 2021.
Seccomp profiles
Seccomp (secure computing mode) is an opt-in Linux kernel feature that restricts the system calls that a container can make. Seccomp profiles can be used to allowlist or blocklist certain system calls, which can help prevent container breakout attacks.
Linux Security Module isolation
SELinux and AppArmor are two common Linux Security Modules (LSM) that can be used to provide further protection and isolation of containers from their host. All of these technologies enable the kernel to provide the features that modern containers rely on to achieve isolation. They also make the job of an EDR much more complicated. More on this later.
As stated before, the Linux kernel doesn’t have the concept of a container. To understand this better, let’s look at an example of a process running in a container. A process in a container is still just a process from the point of view of the kernel. That process just has a set of restrictions placed on it that it shares with itself and other processes inside of a “container.” These restrictions are things like namespaces, cgroups, seccomp profiles etc. But as far as the Linux kernel is concerned, a process in a container is still just a process.
If there is one thing to take away from this blog post it’s this: a container, as we commonly think of it, is just a combination of multiple technologies provided by the Linux kernel to create a new type of abstraction and isolation.
A container is just a combination of multiple technologies provided by the Linux kernel to create a new type of abstraction and isolation.
A quick primer on EDR
An EDR tool gathers process information by monitoring endpoint activity in real time. EDR solutions typically install lightweight agents on endpoints that collect telemetry data about process activity, network connections, and system events. This telemetry data is then analyzed locally based on some rules and/or transmitted to a central server, where it is analyzed and correlated with other events to identify potential security threats.
To gather process information, EDR agents monitor processes running on endpoints, including information about the PID, parent process, command-line arguments, and other relevant metadata. They often gather other pieces of telemetry such as network events, file modification events, script load events, and more. EDR tools also use behavioral analysis techniques to identify suspicious process activity. For example, an EDR tool may monitor for processes attempting to execute in unusual locations or attempting to communicate with known malicious domains. Additionally, EDR solutions may use machine learning algorithms to identify anomalous process behavior based on historical data and patterns of activity.
Once the EDR tool has identified a potentially malicious process, it can provide detailed information about the process and any associated activity, such as files created or network connections established. This information can help security analysts determine the nature and severity of the threat and take appropriate action to remediate the issue.
EDR sensors typically do at least some amount of kernel-level monitoring. Kernel-level monitoring may involve installing a Linux kernel module or using other tools such as audit or eBPF. These mechanisms provide visibility into the operating system’s kernel and enable the EDR solution to monitor all process activity in real time.
Kernel-level monitoring is generally considered more powerful and accurate than user-level monitoring.
So going back to the idea of containers being an amalgamation of various kernel technologies, how does an EDR become container aware? And what does it even mean? Well, it’s actually quite simple. When a process runs inside of a container, the EDR sees it as just a process. The only difference is that a process in a container has some extra restrictions placed on it. But wait, didn’t I just tell you that EDRs have a hard time monitoring containers?
Challenges for EDR vendors
So if an EDR sees a container process as a process, then what is the challenge when monitoring containers? At Red Canary, we integrate with many different EDR sensors, and we also build and maintain our own Linux EDR agent. Through this, we have learned many things about the difficulties of building a production-ready EDR product. Let’s take a look at some of the challenges we have faced when trying to build “container -aware” EDR.
Lack of context
Containers are often deployed as part of a larger application stack, which can make it hard to identify the parameters used when running a container. EDR vendors may need to correlate data from multiple sources, such as network traffic and system logs, to get a complete picture of container activity. This is made especially difficult nowadays since so many of these services are provided via cloud APIs. It’s not always apparent how a particular container is being used in the larger scheme of things.
Another potential issue here is that container engines provide a huge amount of configurability for any given container. Because of this, it is possible to have containers that break the model described above, where there is a near complete isolation of container resources. Privileged containers are a great example of this; they have the ability to mount host volumes to get a view of the host file system as well as view other host resources directly. It’s not always readily apparent to an EDR what access a container may have to host resources.
Lastly, EDR and security analysts tend to rely heavily on process ancestry to detect malicious behavior and effectively understand and remediate threats. For containers, it is common that a shell command to launch a container will not be correlated through process ancestry with the container that starts up. This is because the request to create a container happens through an API to the container engine. Because of this, there is no parent/child relationship between the shell command and the resulting container process. This also means that the user ID (UID) and group ID (GID) association between the shell command and the container would not match up either. It’s possible that the command may even spawn a container on another machine! So even though we see a process start, that doesn’t necessarily mean we can make a meaningful detection with that data.
Security analysts tend to rely heavily on process ancestry to detect malicious behavior and effectively understand and remediate threats.
Short-lived containers
Containers are designed to be ephemeral, with new instances created and destroyed on demand. This means that EDR vendors may only have a small window of opportunity to detect and respond to threats before the container is destroyed.
Difficulty viewing container filesystems
Typically EDRs will enrich data that relates to the events they see. For example, it might try and get the SHA-256 hash of a binary that was executed. Or it may try and get the contents of a script that was run. In both of these cases, the EDR needs to be able to “see” the file as the container sees it. Because containers have their own root directory that is not the same as the host, this becomes a fairly difficult task. This difficulty is compounded by the ability to use different storage drivers to support different filesystem types such as overlayfs, btrfs, etc. Additionally, containers are often short lived, and so the view of the file seen by the container may be gone by the time the EDR tries to view it, adding even further to the complexity.
Differences between container engines
Since the kernel has no concept of a “container,” fields such as container ID or pod ID are not available through traditional kernel-level monitoring. Instead, you need to infer those values based on how a container engine may leverage certain kernel features. Each container engine may have its own conventions for how they build containers. This means that for an EDR to effectively monitor container activity, they need to have some level of understanding of the various container engines.
Resource limitations
Containers, and the hosts they run on, are typically limited in the amount of resources they can use, which can make it difficult for EDR vendors to run resource-intensive monitoring tools within the container or on the host. This can limit the effectiveness of EDR monitoring and make it more difficult to detect security threats.
Enter Linux EDR
Red Canary Linux EDR was designed to handle the challenges of running inside of heavily containerized environments. Let’s look at how EDRs, and specifically how Linux EDR, can address some of the challenges mentioned previously.
Lack of context
EDRs can combine endpoint telemetry with logs from higher-level tools. By integrating with higher-level tools like container orchestration platforms, EDRs can gather additional context that can help them better understand container activity and detect potential security threats. Linux EDR is able to capture container IDs and pod IDs, which can be useful when threat hunting or when trying to understand where a threat came from.
Short-lived containers
Linux EDR can leverage audit or eBPF. These technologies allow it to see events as they happen in real time. This allows it to capture events as they occur inside a container, even if the container is short-lived. It also provides the best chance to gather enrichment data while the container is still running.
Difficulty viewing container filesystems
Since EDRs typically operate at the kernel level, they can see past certain container isolation methods, such as PID or network namespaces. Linux EDR has the added capability of being able to track container filesystems as well. This ability allows Linux EDR to correlate filesystem activity such as script loads, binary execution, or file modifications with the specific container that caused the activity. It can then reach inside that container’s own filesystem to get metadata or, in some cases, the file contents itself as the container sees it.
Gaining process visibility within containers has been a historical problem for EDRs. For example, we created a container that ran a script from a custom path /app/somescript.sh that only existed in the containers filesystem. The EDR would not have information like hash or script contents that it would otherwise gather when the same script was run directly on the host since it was not able to read the contents of the file.
Alternatively, when the same script was run on both the host and in a container—and Linux EDR was monitoring that system—we see that it was able to successfully collect the hash and the contents of the script.

Resource limitations
Linux EDR, from its inception, was designed to be resource efficient. It does this by using Rust—a language known to be lightweight and stable—by doing most of the processing in the cloud, and allowing resource limits to be placed on it so as not to consume more resources than the user wants to allow. These design decisions make Linux EDR an attractive choice for production systems.
Conclusion
As cloud technology continues to evolve, EDRs will have to evolve with it. At Red Canary, many different teams work together to ensure we stay up to date with the latest technologies as well as the latest threats and ensure that Linux EDR is capable of providing clear, concise, and complete data about those threats. We also strive to ensure that our team of detection engineers can effectively use that data to provide cutting-edge detection capabilities as well as a clear picture of what happens when a threat does occur.
Related Articles
Patching for persistence: How DripDropper Linux malware moves through the cloud
eBPFmon: A new tool for exploring and interacting with eBPF applications