
I recently had the pleasure of moderating a webinar on response operations with a panel of security leaders who shared their insights and expertise. It was a lively discussion that addressed everything from prioritizing alerts across your toolset to identifying which key metrics to track in order to demonstrate efficacy.
Whether you have an IR program in place and want to take it to the next level, or have no IR capability and are looking to build one, our panelists provided helpful guidance and actionable recommendations. (Unfortunately, we ran out of time before covering celestial navigation—sorry, Tim Collyer.)
Here are the top 6 questions and answers from our response operations webinar:
Q: Incident response is a huge topic and many security professionals are overwhelmed with where to start. What are the pillars of a good IR program?
Mike Haag, Advanced Threat Detection: To simplify things, we can break IR operations into a high-level framework with three different parts: detection, triage/response, and feedback. Everything we do is based off a detected event. First an alert would trigger, which would move into triage and response. During triage, we would collect as much info as we could about the event, gather the scope, work to validate what it is and where it came from. From there, feedback plays into how we handle that threat the next time. An IR framework takes time. It’s not something you can do in twenty minutes. It’s a large cycle and an organizational effort.
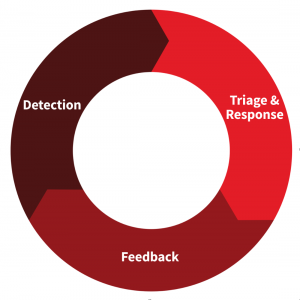
To dig deeper into each stage of the framework, watch the webinar recording and download the slides.
Q: Managing bandwidth through detection and response is a common challenge. When your team has limited bandwidth and is receiving hundreds of alerts from tools, how do you prioritize what to do first?
Bob Argenbright, Security Engineer: Tools give you so many sources of data, with different vendors and different uses, all of which play into our workflow at Heroku and how we prioritize. You need to have context into critical systems, services, alerts, and threat knowledge in order to define prioritization. In my experience, the better approach is to start with a minimal amount of detection and prioritize a small subset to make sure you know what those alerts mean, what the underlying threats are, and then build from there. Once you turn on the fire hose of putting in a vendor’s product and turning on all the rules, it will take a long time to dig out of the pile of alerts. A lot of it is simply knowing your environment and what the alerts actually mean.
Mike: What I found worked in the past when we were getting inundated with alerts was building out an impact matrix and building a process to make it easier for each product. It still takes time because you have to go product by product, building out use cases for each specific one. Meanwhile, your alerts are still building up, things are still breaking, and you’re focusing on Windows event logs and looking to ensure it is properly detecting things. But breaking it out into an impact matrix can be an extremely helpful approach overall.

Tim Collyer, Information Security Manager: It’s definitely a challenge when your organization has been around for a while. At Motorola Solutions, we have old tools, evolving threats, new gaps, and new visibility requirements. It requires us to constantly juggle and evaluate whether the tools we have in place still meet our needs or if they should be replaced. An important aspect in terms of effectiveness is whether a tool is created by a vendor or homegrown. Motorola Solutions is a larger organization, so we have the capability to build our own tools, and it’s always interesting to determine whether or not that’s the right choice. There are strengths and drawbacks with each approach. Homegrown tools are great for flexibility and customization, but the challenge is that you’re depending on a team of people who know the tool and maintaining it through turnover. In that case, it’s nice to have a vendor who provides support and structure, which also has the benefit of saving the internal team the time of developing it themselves.
Read more on the “Build vs Buy” debate
Q: Do you need a SIEM to successfully prioritize alerts?
Bob: It depends on the amount of data you’re handling and what that data means to you. If you’re in an environment with 1K+ endpoints, that will be too much data to handle just by looking at a few different systems like a firewall and IDS. Alternatively, a SIEM can actually take in alerts and prioritize those for you—if it’s configured correctly. Many SIEM deployments are not being used effectively due to a lack of resources. It takes a lot to have all your data sources in the right place, understand all the data, and create meaningful alerts from that product.
In my experience, one big thing that has helped prioritization and assignment is being able to categorize your data in a way that makes sense, and applying resources to the SIEM or the devices themselves in order to tune them and make them effective. Today’s technology is more responsive to customers’ needs, but that requires more customization on our part. Nobody has an identical network. Nobody has identical people and processes. We’ll always need to adapt tools to be effectively used in our workflow with the amount of resources that we have.
Q: Metrics, metrics, metrics. This is one of the most common areas we receive questions around. What should organizations track in order to measure continuous improvement?
Mike: After an incident, you have all this data. We would take the information and generate a report out to the business. Whether it was certain pieces of software that were vulnerable or other high-level pieces for improvement mixed with the overall reporting of the investigation, we would look at things based on the product effectiveness and the amount of data coming from that. How many of these alerts converted to actual investigations? False positives and negative rates play an important role. At Danaher, we found we had key, core products producing high-value alerts and we’d spend more time on those versus lower products producing a ton of alerts but very low true positive rates for us to investigate. That information would help us go back and improve those products, either by building new use cases or finding new ways to generate more high fidelity alerts so we weren’t having a product just sitting there decaying.

Get a list of what metrics to track by downloading the response operations webinar slides and recording.
Q: What scoring methodology do you use? Is it based on tools or severity? How do you measure that and ensure your effectiveness is always improving?
Joe Moles, Lead Detection Operations: At Red Canary, this is a big thing for us. The approach we take is very simple—we look at each signature or behavior and assign a score based on whether it converted to a high, medium, or low notification to our customer. We take that and multiply it by whether it was a true positive or a false positive based on the percentage of total events generated, which gives us an aggregate score, and we use that to drive prioritization of what gets presented to an analyst. We also use those values and conversion rates to drive our internal tuning and determine if we have something that is potentially causing alert fatigue, not providing value, and consuming more analyst time than we want it to.
Take a deep dive into a recent threat Joe Moles detected on the Ask.com toolbar.
In my previous role at OfficeMax I used similar ideas, where we’d track how often things were converting. It’s not the number of events that matters, but the percentage of the conversion rate being something we could act on. We’d prioritize things that weren’t converting for tuning based on how much time they were consuming and look for opportunities to reduce the noise.
Q: Any last words of advice for organizations who are just getting started?
Tim: Feedback is one of the first things to work on in developing IR operations. If there’s any one measure of the maturity of your program, it’s whether or not you have some sort of feedback loop. You need to be able to show you’re learning from what you’re doing. It helps analysts be happier and faster, and it lets you demonstrate the efficacy of what you’re doing to management.
Joe: Start with a small piece. Don’t try to do it across all your tools. If you have a particular tool that you think should have a high value but is supremely noisy, look at that and see where there are opportunities within the environment to tune out some of that noise. Identify the cause of alerts to certain users or systems and take action to tune and address that, then feed it back into the system. This is where we close the loop. Take every opportunity to tune, identify, and get higher and higher fidelity based on your learnings. The other piece we focus on is looking back to see if there’s anything we missed and could have found faster or better. We then use that to drive new detection capabilities, putting it back in the system to make sure we find it next time, faster.
WATCH ON DEMAND: How to Take Control of Your Response Operations