
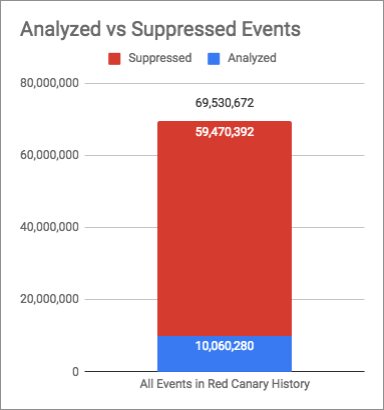
In roughly five years, more than 69 million events have entered our detection engine. Just 10 million had to be analyzed by our detection engineers. So what happened to the other 59 million events?
In this article, we want to take you on a short journey into a critical piece of the Red Canary engine that may help explain how we are able to manage the massive amount of telemetry data received on a daily basis.
Automation is cool, but there is an older… deeper magic
We’ve previously discussed the benefits of automation, and how it’s helped maintain timely detections. While automation is key, there is another component to the analysis process that happens much further up the chain and that security teams have been using for years: suppression.
We actually like drinking from the firehose
Our philosophy is that the cost of sorting through massive troves of data is less than the risk associated with potentially missing something, which could easily occur if we were more selective about what we analyzed. Suppression enables the Red Canary engine to ingest all of the relevant information we need without inundating our detection engineers. This may sound like a large amount of overhead, but there have been plenty of situations where a compromise would not have been caught if we hadn’t ingested and analyzed all of the data we have available.
One example of this was when we found a customer’s server making an external network connection to a foreign government’s top level domain. We were alerted to the behavior thanks to an extremely broad detector that was tuned to identify instances of regsvr32.exe—the Windows tool used to register and unregister objects such as Dynamic Link Libraries (DLLs)—making external network connections. This type of behavior should generally be regarded as suspicious, but there was no additional behavior that would have otherwise set off red flags for us. Furthermore, there were multiple external network connections being established, not just this one that we ended up alerting the customer about. Ultimately, the reason why we were able to catch this was because we did not preemptively inhibit our visibility into our customer’s environment by limiting the amount of data we collected from it.
It is also worth noting that sometimes we discover that our broad detectors are giving us too many false positives. One of the ways we combat this problem is by dividing broad detectors into more narrowly focused detectors looking for similar variations of the same behavior. This allows us to maintain the coverage we had with the broad detector while also reducing the amount of time it takes a detection engineer to identify a threat.
When it comes to telemetry data, the more of it that is obtained from our customer’s endpoints, the better our analysis will be. In fact, every day Red Canary is ingesting approximately 200-250 terabytes of data. For comparison purposes, that’s about 340,000 hours worth of digital music. Our ingress data rate is constantly increasing, and this naturally brings up concerns about scaling in various parts of the engine—including one of the more fragile parts: human analysis.
Generally speaking, humans have a finite number of resources available, so one solution to analyze an ever-growing pool of data is to throw money at the problem by hiring more humans. Another is to increase efficiencies in the backend so that the machine can do what machines do best: perform repetitive tasks. This is what Red Canary decided to do early on when we introduced our suppression engine. The idea was not really anything revolutionary—create rules to match specific patterns of data and drop them before reaching a human—but because it was implemented from an early stage, it has greatly helped us continue to scale upwards.
Getting what matters from the firehose into a garden hose
Without hiring a small army of detection engineers to analyze it all, it would be impossible for us to sift through all that data and still be able to deliver timely detections to our customers. Furthermore, there is no benefit to analyzing the exact same binary or process behavior after it has been determined to be a false positive. With the suppression engine, we are able to manage this by creating broad or specific rules on the fly as the team is analyzing events. This is also done without requiring an approval process, which empowers our detection engineers to reap the benefits of suppression immediately. To be clear: we routinely review suppression rules to make sure human error is not ignored.
In order to combat floods of events, another option would be for Red Canary to have a dedicated team of detector developers to constantly play whack-a-mole by continually modifying our detector set. It is commonplace for us to start monitoring a new environment in which administrators are running scripts that exhibit behaviors or specific command line parameters that we have previously observed in association with malicious activity—and for which we have developed a detector or two. In this way, the innocuous behaviors of one customer’s systems administrator can repeatedly raise events designed to alert on behaviors that we have previously associated with adversaries.
We have also found that inventory management software is frequently the source of false positive events raised to the CIRT because this software often operates in ways that are consistent with malicious reconnaissance behaviors. Of course, this is only one example and there are numerous legitimate applications that we have observed performing actions that can trigger our broad detectors and that we have suppressed from our daily operations accordingly.
When one of our detection engineers encounters an event and determines that it is a false positive, he or she can then create a suppression rule that requires, at the very least, two pieces of information: the MD5 hash of the process that executed and the detector that raised the event to the queue. For some of our detectors that are more broad, it can be this simple in order to suppress a binary that triggered a detector due to, for instance, it executing from an unusual location on the host and not having having a valid digital signature. This is usually not the case, though, and instead any number of other artifacts need to be selected to create a suitable suppression rule.
Along with the MD5 of the executing process, suppression rules can currently be made with a variety of other options, as shown below.
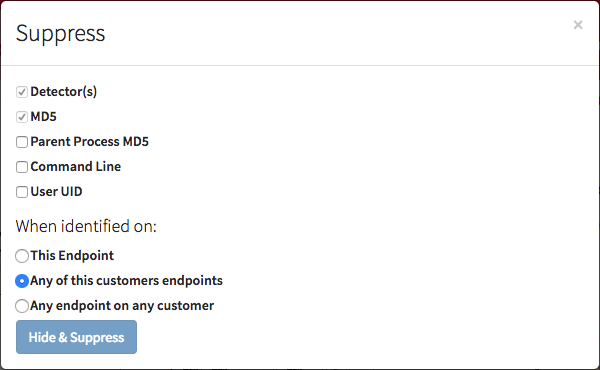
Keeping in mind that each of the options relate to the process being analyzed, here is some additional explanation.
- Parent Process MD5: refers to the MD5 hash of the process which spawned the one being analyzed
- Command Line: the command line executing with the process
- User UID: the user that the process is executing as
With the various options available to the detection engineering team, suppression rules are able to be fairly granular and specific. The suppression options can also be combined in order to be even more granular, but the more specific a suppression rule becomes, the less effective it will be at reducing the number of false positive events. It is important for the detection engineer to select the correct options for the rule, not only to make sure it is an effective one, but also to make sure that it is not so overly broad that it prevents malicious events from reaching the analysis queue.
For example, attackers will often take advantage of PowerShell to perform a variety of malicious actions while using a base64-encoded command line to hide their actions. We have a variety of detectors that trigger on behavior related to this type of attack, but there is still a great deal of benign administrative activity that will generate events as well. Making the detectors more specific to known attacks is one option, but the attack methods are constantly changing, so it is better to keep them broad and naturally noisy. The solution, assuming some event was determined to be a false positive, is to create a suppression rule based on both the MD5 of PowerShell and the specific command line. Furthermore, if the parent process provides additional context for the behavior, then adding that option (Parent Process MD5) to the suppression rule can greatly reduce false positives.
At this point, you may have also thought about how long suppression rules should stay active after they are created. Initially, Red Canary automatically expired suppression rules 90 days after they were created. This was to ensure that we periodically reconsidered whether or not an observed behavior continues to constitute a false positive. A side-effect of this was that every 90 days the CIRT received a flood of previously suppressed behaviors that would generally need to be re-suppressed. After enduring a few of these quarterly floods, we decided to add the option of a permanent suppression rule. After identifying a false positive that has been suppressed multiple times, we further analyze the behavior to determine whether it should be made permanent.
Continuous re-optimization of the fire hose
Red Canary’s operation did not always have the suppression engine. At first, the only option when a false positive was identified was to “hide” the event, which removed it from the analysis queue. This worked well at first, but as we added more customers and began monitoring more endpoints, the number of events showing up in the analysis queue started to overwhelm our detection engineers. The first iteration of suppression allowed for rule creation only on the MD5 of the executing process and whether to apply that rule to the single endpoint, the entire customer, or all customers. Again, this worked for a while, but soon we had problems scaling as we took on new customers and as we developed new detectors to identify additional malicious behavior in the command line execution.
The current version of the suppression engine with its available suppression options is able to handle most of the CIRT’s needs when a false positive arises. Meanwhile, we’re continually evaluating additional options to continuously improve as we scale. One idea that has been thrown around is the use of wildcards or even regex in the process command line. This is due to various instances in which the only reasonable suppression rule to be created is on the “detector” + “binary MD5” + “process command line,” but, unfortunately, this does not always work since command lines often contain specific paths or parameters that may be dynamic.
Check out this on-demand webinar to learn more about how we handle such massive volumes of data
One of the beauties of our product’s code—and the team directly or indirectly involved in its development—is that when we need to make a change, many people have the ability to jump on the problem and quickly come up with a solution. Of course, this isn’t the Wild West. We have a review process, but changes are generally peer-reviewed the same day, if not the same hour. Discussions occur inline with the suggested modifications to the product code, allowing for quick turnaround times to the benefit of both the detection engineering team and Red Canary’s customers.
Conclusion
To be very clear: we did not and are not claiming to have invented suppression. However, we do use it on a daily basis in order to keep the detection engineers in our CIRT from becoming overrun with meaningless false positive alerts and to ensure that our customers receive valuable information in a timely manner. Similar to getting stuck in the weeds when doing threat analysis, it is easy to fall into the rabbit hole of over-engineering instead of looking at the problem holistically and coming up with a simple solution. Suppression is a simple solution that nearly any security team can use to help cut through the noise.
Related Articles
The dual-use dilemma: Rethinking detection for remote access tool abuse