
2024 is shaping up to be the year of identity attacks, as adversaries leverage both novel and familiar tactics to get their hands on users’ credentials. One tried-and-true method for account compromise is bruce forcing, wherein an attacker “forces” their way into a login by entering as many password combinations as possible.
To tackle the challenge of identifying IP addresses involved in brute-force attacks, the Red Canary threat hunting team adopted a detection strategy based on a comprehensive watchlist. By leveraging trends, aggregates, and statistics across our customer base, we built an effective watchlist for detecting suspicious or malicious activity on user accounts. Our aim was to develop a robust strategy, integrate it into a detector, smartly populate the watchlist, and evaluate suppression mechanisms to ensure exceptional performance at Red Canary, meaning a low number of false positives without over-suppression.
Choosing a methodology
We explored three methods for creating this watchlist and ultimately decided to focus on the third approach. The methods we considered were:
- tracking multiple failed logins from an IP across various customer environments—which helps identify IPs that repeatedly fail logins in different contexts
- assessing the ratio of successful to failed login events for specific IPs in each customer environment—providing insights into the behavior of IPs within individual environments
- counting multiple failed login attempts across our customer base and identifying outliers using the Z-score statistical measurement—which allows us to spot IPs that deviate significantly from the norm across our entire dataset
We chose the Z-score method because it allowed us to test effective detection and suppression strategies with the most accuracy. While relying solely on outliers can result in many false positives, this method offers a more nuanced way to identify suspicious activity. By leveraging IPQS data points—such as high fraud scores and recent abuse reports—along with organizational details we have access to, we created a contextually aware detector that minimized false positives, generating approximately 20 events per week for review.
With this approach, we successfully identified approximately 70 compromised accounts across four different customer environments. Testing this brute-force detector allowed us to enhance our coverage in the identity space while advancing our research and development into customer-specific detections tailored to unique activities. While setting up brute-force detectors might seem straightforward, achieving near-flawless performance across diverse environments demands careful attention to list creation and suppression techniques, which we explore in greater detail below.
Note: We decided to focus our research on Google Workspace.
Building detection logic
Crafting the logic for our Z-score analysis was relatively straightforward. We began by collecting all login failure events over a seven-day period, which was long enough to capture multiple brute-force attempts from the same IP before IPs were rotated or a campaign ended. We then counted how frequently each IP appeared in this dataset. While a simpler approach might be to set a threshold (e.g., flagging IPs seen more than five times), we opted for a more nuanced analysis using the Z-score.
The Z-score measures how much a value deviates from the average, making it an effective tool for identifying outliers. For instance, if an IP address appears significantly more often than others, it will stand out. Rather than relying on a fixed threshold, such as five appearances, the Z-score helps us detect deviations where an IP might appear 150 times while others appear only one-to-five times, without explicitly setting a count of appearance threshold in code. The example below shows that among 10 IPs, one stands out significantly as an outlier because it is more than three standard deviations from the norm in this dataset. Adding more IPs could further highlight outliers based on our Z-score criteria.
import numpy as np
ips = {'1.1.1.1': 1, '1.1.1.2': 1, '1.1.1.3': 1, '1.1.1.4': 1, '1.1.1.5': 2, '1.1.1.6': 1, '1.1.1.7': 3, '1.1.1.8': 5, '1.1.1.9': 3, '1.1.1.10': 2, '1.1.1.11': 24}
x = np.array(list(ips.values()))
std = np.std(x)
mean = np.mean(x)
z_scores = abs((x - mean) / std)
threshold = 3
result = np.where(z_scores > threshold)
for i in result[0]:
print(f"IP: {list(ips.keys())[i]} has a z-score of {z_scores[i]}")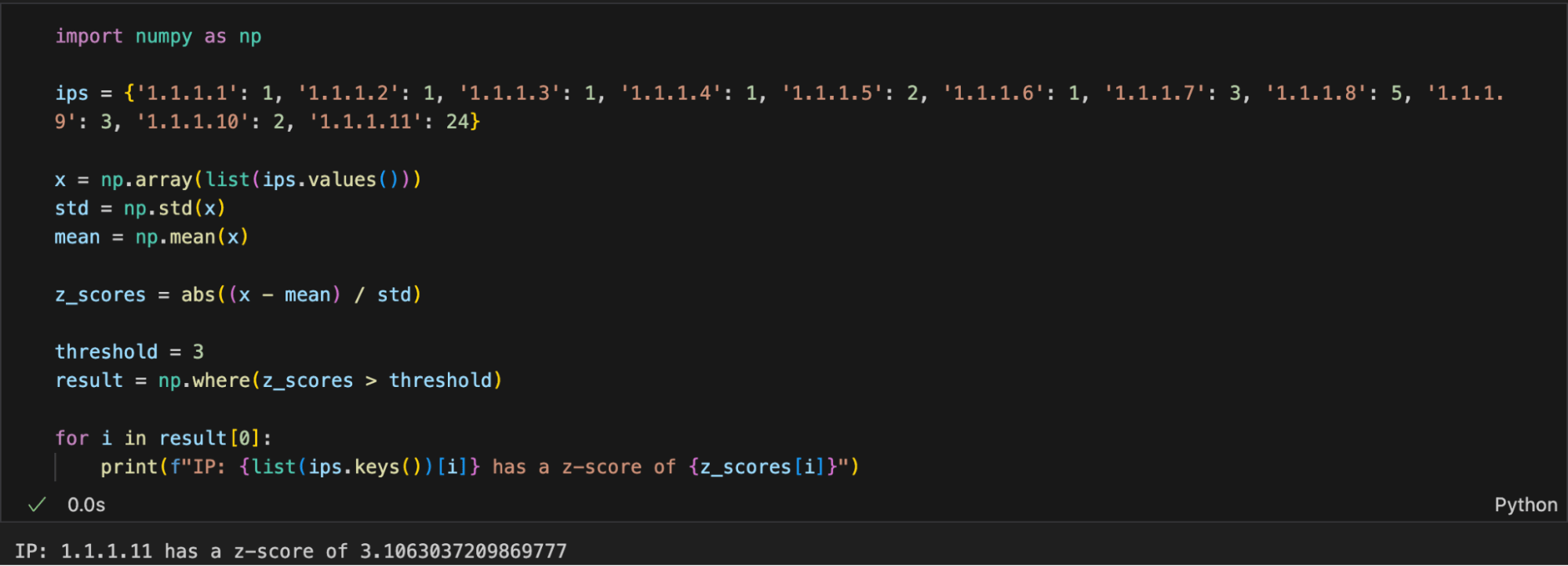
We found the following resources helpful while creating this detection logic:
- Outlier detection and removal: z score, standard deviation | Feature engineering tutorial python # 3
- ck12.org normal distribution problems: z-score | Probability and Statistics | Khan Academy
Tuning with targeted suppression
Now that we have a sophisticated method for identifying outliers, we can query for successful logon events. However, a high count of login failures from an IP alone doesn’t necessarily indicate malicious activity—it’s merely a red flag that warrants closer examination. Running a query for any successful logins from the flagged IPs initially resulted in a lot of false positives. Without making a change in suppression, alert fatigue would be inevitable, completely undermining our efforts by overwhelming analysts with alerts of benign logins.
The high-false positive rate underscored the importance of testing suppression mechanisms. During testing, we found that we could easily suppress certain IPs for individual organizations by leveraging the IPQS Proxy Detection API. This API offers a continuously updated database with details like recent reports of fraudulent activity and valuable enrichment information, including the associated ASN, ISP, and registered organization.
For example, many IPs associated with educational institutions appeared on the watchlist because students and staff often authenticate from the same IP. Many of these school IPs were flagged by IPQS as associated with fraud, which led to their initial inclusion on our watchlist. While this suggested that suspicious or anomalous logins from IPs associated with brute-force attacks were occurring, these IPs were actually benign for the organization. By leveraging IPQS for our enrichment and refining our detection logic, we implemented targeted suppression based on trusted networks and organizations. This ensures that suppression is applied appropriately within each of our customers’ environments, enhancing the precision of our detection while minimizing false positives.
By leveraging IPQS enrichment and refining our detection logic, we implemented targeted suppression based on trusted networks and organizations.
A few caveats are worth mentioning. We might encounter a situation where our check for whether an IP has been recently associated with fraudulent activity occurs before the IPQS database is updated with reports of fraud for the IP. This could lead to misidentifying IPs as non-malicious depending on the timing of the assessment. To address this and save on API usage, we cache the report for each IP locally. If an IP is initially deemed not associated with fraudulent activity, we move it to a discarded list, which is kept alongside the active list for our watchlist. This setup achieves two key objectives:
- performing manual quality checks
- automating frequent polling of IPQS for updated reports on a set schedule
If the IPQS database is updated and the IP meets our predefined “suspicious” criteria, we move it to our active list and update our cache accordingly. This ensures that reports are current (within the last 24 hours) for our analysts to review for additional context when deciding whether to publish a threat, while also assessing other factors like the user’s previous login history to identify if the login is truly anomalous, all while keeping API usage minimal and ensuring our watchlist remains up to date and accurate when flagging an IP as being associated with brute force.
The final product
Now that we have the IPs we want to examine, we’ve enriched them using IPQS and developed a strategy for implementing domain-level suppression. Our logic for collecting and assessing IPs, appending them to our watchlist, and triggering alerts is as follows:
# Initialize an empty dictionary to collect IPs
collected_ips = {}
for ip in login_failures_last_x_days:
if ip not in suppressed: # Skip benign IPs that we have already reviewed and determined to be safe globally
if ip in collected_ips:
collected_ips[ip] += 1
else:
collected_ips[ip] = 1
# Calculate the standard deviation and mean of the IP counts
std = calculate_std(collected_ips.values())
mean = calculate_mean(collected_ips.values())
# Compute the Z-scores for each IP address
z_scores = {ip: (count - mean) / std for ip, count in collected_ips.items()}
# Iterate over each IP address and its Z-score
for ip, z_score in z_scores.items():
if z_score > 3:
ipqs_info = ipqs_api(ip) # enrich the IP address with IPQS
if (ipqs_info['fraud_score'] >= 85 or ipqs_info['recent_abuse'] == True):
add_to_brute_force_active_watchlist(ip) # Add the IP address to the brute-force watchlist, to allow for continuous requerying of successful logins from flagged IPs
if (ipqs_info['organization'] not in trusted_organizations and ip not in trusted_network_ranges):
if login_successes_last_x_days: # Check for any recent successful logins
for success in login_successes_last_x_days:
alert # Generate alert for successful login from suspected IP associated with brute-force.
else:
add_to_brute_force_discard_list(ip)
This brute-force detection strategy helped in identifying approximately 70 instances of account compromise across four distinct customer environments, all of which were schools or higher education institutions. This is understandable since students are often encouraged, but not required, to use MFA, leading to many accounts without this extra layer of security. Additionally, lenient password complexity and rotation policies contribute to accounts being easily compromised due to weak or leaked passwords. All affected customers have been notified, and in response we recommended resetting the user’s password, revoking any active sessions, resetting the user’s MFA properties where applicable, and encouraging enforcement of MFA in the future.
Continuous improvement
The strategy we’ve described and implemented here is straightforward and effective with the right components, but it could be enhanced by considering both the frequency of failed logins and the IPs associated with those logins across multiple customer environments. For instance, if an IP is associated with several failed logins in multiple tenants, it may signal a significant threat. While using the Z-Score method to identify outliers is one approach, flagging IPs based on failed logins across disparate organizations could also be effective. Given our reliance on IPQS within our detection logic, incorporating multiple methods to populate our watchlist in the future will be essential. We have already begun this process to enhance coverage and avoid over-reliance on any single method.
Looking ahead, a more advanced approach could involve detecting and assessing anomalies (in-code) for each user logging in from an IP on the watchlist (which we are actively working on). This strategy would enhance our ability to assess identity threats, reduce human analysis time, and focus on genuinely anomalous behavior. A user-centric approach offers a more nuanced method compared to broad domain-level detection, especially in remote work environments with inconsistent VPN policies.
Related Articles
Moving up the Assemblyline: Exposing malicious code in browser extensions
Hunting for malicious OpenClaw AI in the modern enterprise
Hunting for malicious OpenClaw AI in the modern enterprise
Breaking down a supply chain attack leveraging a malicious Google Workspace OAuth app
Breaking down a supply chain attack leveraging a malicious Google Workspace OAuth app
The million-dollar front door and the tailgater: Why strong auth could fail at SaaS session integrity