
As an analyst, reviewing events generally takes up a pretty good chunk of your day. And as much as there is a lot of hype about moving away from “signature-based detection,” many detection solutions are at their core just based on a rule (or set of rules) with some Boolean logic and pattern matching. That’s not to say they aren’t leaps and bounds more flexible (and complex) than a standard IOC hit such as an MD5. It’s just that many of them are not some crazy complicated ML/AI algorithm that the average analyst has little hope of understanding.
Deciphering events and tuning to minimize noise becomes a lot more straightforward once you get used to the patterns and know what to look for. This article will outline:
- A 3-step process to help analysts identify a signature’s purpose and minimize unnecessary noise
- Examples to illustrate the analysis process across various types of events
- Ideas for research you can do on how to make a rule better
3 Steps to Analyzing Events and Minimizing Noise
Step 1: Identify the event’s purpose.
Half the battle can be trying to figure out what threat the event was supposed to detect in the first place. Before doing anything else, ask yourself: do you understand the behavior or pattern the signature is looking for and what it actually is? If not, can you even find out? This seems somewhat self-evident, but making sure events are valid for the threat they are trying to detect should be part of your initial review.
If you have access to the actual rule (and relevant data) you can hopefully see exactly what caused something to trigger an event and then determine if it is desired. Even better, you may be able to access previous examples of “badness” to compare that what you’re seeing is a match. But sometimes all you have to go on is a signature called something like ‘JBOSS-EXPLOIT,’ which tells you almost nothing except that it’s JBOSS… and it’s an exploit… So then where do you start?
You can still do some initial vetting to answer questions like:
- Is the system running JBOSS?
- What version is the system running?
- What exploits have been published for that version?
It’s a lot more difficult for sure, and you may have to settle for “I’m reasonably sure this is not something we need to be concerned about” without an exact why.
Let’s look at a few examples to illustrate this process across various types of events.
Example A: It matches, but does that mean it’s bad?
A simple example would be if the signature is looking for the process names containing the string ‘cain,’ with the intent to alert the analyst on potential execution of the popular password cracker ‘Cain & Abel.’ (Why Cain over Abel, you wonder? Think about how many words contain ‘abel.’) If the event was for a process called ‘lydocaine.exe’ you would have an event that triggered correctly, but it’s not at all what you’re looking for so you can quickly move on.
The following example is an executable that contains the letters ‘wce’, which is another password cracking tool. As you can see, the executable is actually webex related and simply contains ‘wce’ in the filename. It matches, but it’s not bad.
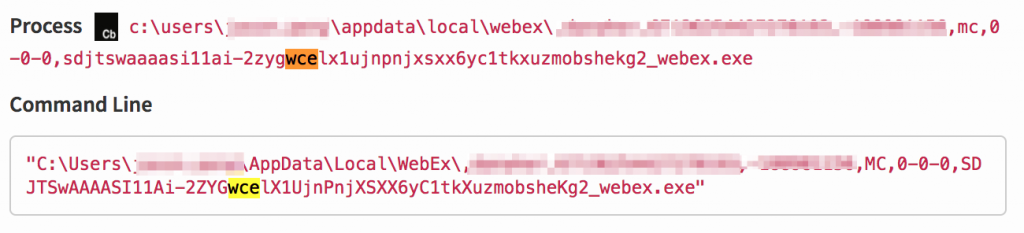
Example B: Your environment has something outside of normal.
Another basic example is if you happen to be in an environment where you run HTTP over port 8080 and you keep getting hits for HTTP over non-standard port. Yes, the rule is firing as intended but it needs to be modified or ignored in your environment. The key takeaway, though, is that if you have an event for a network-related threat, don’t immediately jump to looking at child processes and modloads. Or if it’s a Linux host, don’t spend cycles when an event is related to something that only affects Windows—except maybe to figure out how to not see events like that again.
Example C: You are using PowerShell Frameworks.
For a more specific, but still basic example, let’s look at detection efforts for PowerShell. With all the PowerShell frameworks that are out there trying to obfuscate commands, you should generally try to be as broad as possible in detection efforts for PowerShell arguments. However, there is such a thing as being too broad.
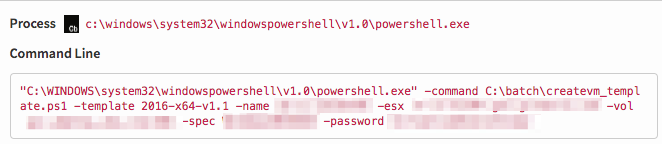
Below is an example of a rule that fired on a PowerShell command. It was looking for variants of the ‘-Encoded’ argument, which is used primarily to pass an argument as base64 encoded text, but it’s not limited to this. In the event below, you can see the only command that starts with ‘-e’ is ‘esx.’ Because it’s nowhere near what the behavior we’re looking for is, with a very quick glance we can move on. I’ll come back to this event again, because it also illustrates why you should validate that something was written correctly to begin with (if you can) after reviewing.
RELATED RESOURCE: PowerShell Abuse: Good Tool Gone Bad
Step 2: Determine the value of the signature.
Many times you walk into an environment where there are a ton of existing signatures from a myriad of different sources such as vendor proprietary rules, threat feeds, and custom rules that the security team has created over the lifetime of the SOC. While writing signatures can be research-intensive and challenging, sometimes trying to figure out an existing one that keeps firing is almost more challenging. You didn’t write it, you have no way to talk to the person who did, and of course it’s without great documentation. The naming convention sometimes sucks, there are no examples of what the ‘badness’ actually is—or worse, you can’t even see what’s in the packet, process, or log that caused the rule to trigger in the first place.
The philosophy at some of the organizations where I’ve worked is that it’s better to have a couple extra events than to miss a real threat on the network. However, at some point, you realize it’s taking you the first 10% of your shift to weed through the noise, and you have seen the same event so many times you’re not drilling into it anymore (high miss danger). This means that, in its current state, the rule is providing very little value.
Which leads to…
Step 3: Identify ways to make it better.
Enter “tuning.” In general the word “tune” is used for a change made to an existing signature in order to make it more accurate, or to fix an oversight that would cause a false negative. Many vendors (especially open source or home-grown solutions) provide the ability to tune rules, tailoring them to your specific environment or use case. It doesn’t always have to be done via the detection appliance itself either. If all your logs feed into a central source, you can probably add some filters there, which is especially useful in cases where you don’t have access to the ruleset itself.
Odds are the signatures that really drive you crazy are not the ones that fire once in awhile; it’s the ones that are causing you hundreds to thousands of events day in and day out. If you’re lucky, you have some technical mechanism for filtering them out, but if not (or if it’s an “all or nothing” filter), you may want to make them more granular so they actually provide value.
There are two guidelines I generally recommend when analyzing existing rules:
1: Assume nothing.
Don’t necessarily assume that whoever wrote a signature or rule thought of every corner case and extensively tested before deploying it. Based on the data set they had available at the time of writing, it may have been a very quiet high fidelity alert, but it turns out 99% of the developers on your team use that same technique in the course of their daily activities. Especially if you’re getting signatures from outside sources (or they were written two years ago), they may need to be reworked.
2: Question (and test) everything.
Most rules boil down to a logic pattern. That logic pattern may be as simple as ‘if a == b’ then trigger, or as complex as a string of nested parameters that you have to order of operations it up on a regex ridden pattern. Either way, a solid understanding of logic can really help when trying to fix (or create) signatures. Fortunately, testing logical syntax is something you can do with pretty much any programming language like ruby or python, or a cool app someone on the interwebs wrote.
Whatever method you use, make sure that the inputs you think should trigger an event actually do trigger when run against your syntax. For example, parentheses can matter.
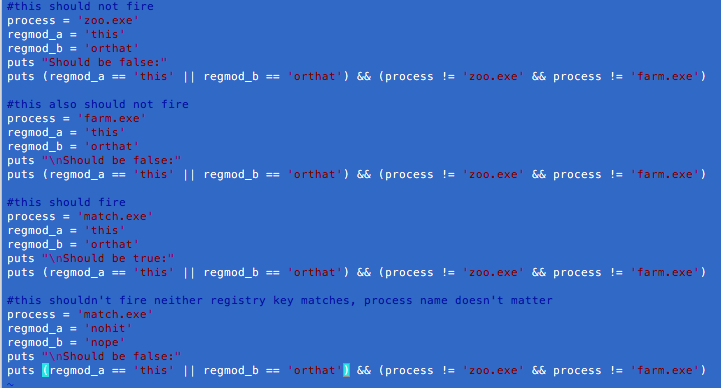
In the following scenario, suppose you want to see events where one of either two registry values is modified, but only if it’s not by either one of two processes.
You initially write it like this:
regmod_a == ‘this’ || regmod_b == ‘that’ && (process != ‘zoo.exe’ && process != ‘farm.exe’)
You then prepare the results that you would expect from feeding in the various input combinations. (Note: In this case, proc can have one and only one value, while reg can of course have multiple modifications per process.)
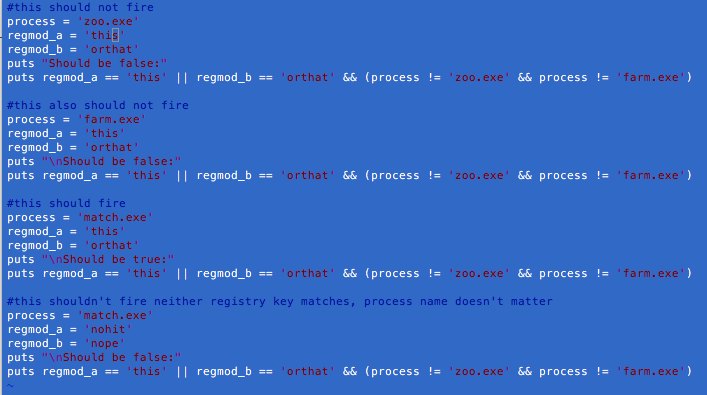
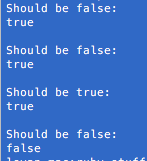
You run it and half of your expected results fail. To some analysts, the reason why will be super obvious, but it just illustrates why it’s important to test out your syntax against known results. A simple thing like not realizing you needed to enclose an expression in parentheses can trigger events you did not actually want—or worse, fail to generate ones you do.
As a side note, the above test is not completely thorough as it doesn’t test out when one or the other regmod value is false. However, it isn’t needed to illustrate the point.
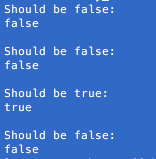
 What you actually wanted was this:
What you actually wanted was this:
(regmod == ‘this’ || regmod == ‘that’) && (process != ‘zoo.exe’ && process != ‘farm.exe’)
Running through a limited number of examples:
 Correct results:
Correct results:
 Now, let’s go back to our PowerShell example from earlier. Remember the “don’t trust that whoever wrote the signature tested every corner case” rule? It turns out that while PowerShell does indeed do ‘-en*, -e*’ when passed an argument, there has to be one and only one match for it to actually work.
Now, let’s go back to our PowerShell example from earlier. Remember the “don’t trust that whoever wrote the signature tested every corner case” rule? It turns out that while PowerShell does indeed do ‘-en*, -e*’ when passed an argument, there has to be one and only one match for it to actually work.
In other words, since -e* matches -esx, -encoded, -error, -enable (-e in an MD5 hash if you don’t add leading whitespace), it is not even a valid way to call ‘-encodedcommand’. While you’re not going to miss any events that you want, you’re also going to generate a lot of events that are nothing like what you’re looking for. If you instead focus on valid variations of -encoding ‘-ec’ and ‘-enc’ – you should end up with mostly events like this which are of interest. This drives up the fidelity of the rule, making it pop out more when you do see it.
Key Takeaways
The end goal is having signatures that are accurate enough to create an event when something of interest appears. But unless they are so high fidelity that they can be automated, remember that a human is looking at pretty much each and every event created. It’s important as an analyst to question if these events are providing value (especially if they are noisy) and whether you can make tweaks to ensure that you spend more time looking at things that are interesting—and therefore increase your likelihood of not missing bad stuff.
More Ideas to Help You Maximize Your Bandwidth:
- Webinar: How to Take Control of Your Response Operations
- 3 Essential Components to Build into Your Incident Response Program in 2017
- Response-Enabled Detection: Can Thinking Backward Move Your Security Forward?
Related Articles
The dual-use dilemma: Rethinking detection for remote access tool abuse