
Recently I’ve been pondering a way of thinking about detection and response. In my mind it is called “Response-Enabled Detection” and it reminds me of the golf strategy of playing a hole backwards.
Most of us amateur golfers stand on the tee box and try to pick a spot to hit the ball based on our current perspective. From there it usually looks like we should grab the driver and hit it as far as we can to set up as short a second shot as possible. We think that is the best way for us to make a lower score on the hole.
On the other hand, high-level golfers start at the hole and think their way back to the tee box. They start with where the hole is on the green (front, middle, or back; left, right, or center) and then think about the approach shot. If the pin is on the left of the green and there is a bunker on the left of the green, it might be better to hit the approach from the right side of the fairway to reduce the risk of going in the bunker. If there is a severe slope on one side of the green, it may be important to consider the risk of losing strokes by accidentally hitting it on that side.

A good player will also consider the ideal distance from the green for their approach shot. Maybe there are slopes or bunkers they want to avoid, so they pick a spot further from the green than they might otherwise. They may also factor in preferences for certain clubs or distances, or favor a particular type of shot they’ve been practicing heavily and about which they feel good.
With the location of the approach shot determined, it’s time to think about the tee shot and pick a club that provides accuracy at the desired distance. A professional player starts with the shortest club possible (shorter club = more consistency = less risk) and talks themselves into a longer club if necessary. An amateur player, on the other hand, typically defaults to a driver and chooses a different club only when forced (e.g. there is a hazard at or near the perceived range of their driver).
Improving Detection and Response: “Response-Enabled Detection”
I wonder if applying a similar “backwards” thought process to detection and response is what we need to move our security programs forward.
A typical approach to improving detection and response goes something like this:
Day 1: Buy cool new magical detection tool.
Day 2: Look at all these amazing things it detected!
Day 3: Ok, this is a lot to get through every day but we have to do it.
Day 4: No way we can possibly get through all this every day, let’s prioritize the alerts.
Day 5: Prioritizing helped, but we’re still getting tons of false positives, so let’s turn some of the detection capabilities off (and what if one of those low-pri things is actually really bad?).
Day 10: Should we really have paid all this money if we were only going to use 10% of the capability?
What if we imagine this as a spectrum instead?

The right side is the perfect world where we literally look at every little thing that happens on our network and endpoints and expertly pluck out the malicious activity. The left side is where we look at nothing and count on detection/prevention products to accurately identify and stop malicious activity. The right side exists only in a fantasy land, and the left side is a good way to make sure all of your money and data gets stolen. So, let’s assume that every company is somewhere between these two rails and the goal is to move as far to the right as possible.
We hear all the time during conferences, webinars, sales pitches, etc. that in order to improve security we have to collect more data, get more visibility, do more correlation, use machine learning. Hell, I’m one of the people who has said this in front of crowds on many occasions. But if you take that advice and you turn detection up to 11 without the response bandwidth to use the alerts to improve your security, have you actually made anything better? Have you moved your position on the spectrum farther to the right? Or have you just created more “security debt?”
A Different Approach: Start by Assessing Your Response Bandwidth
What if we flip this around and start with an assessment of our response bandwidth – that is, how much can we get through on a daily basis? The first step in a response process is to validate the alert. With our current tooling and staff, how many alerts can we validate on any given day? If we know this and we know the volume of alerts our current detection mechanisms create, then we can assess whether we can add more detection and actually make use of it. If we are currently at saturation before we go out looking for new detection tech, we should first consider how we are going to increase our response bandwidth.
There are really only three ways to increase response bandwidth:
- Add more bodies (or a managed security partner)
- Make alert validation more efficient (I’m leaving out the rest of the response process – assessing risk, doing remediation, etc. – but they obviously factor in too)
- Reduce current alert volume either by turning off useless alerts or coalescing multiple alerts into one (technically doesn’t increase bandwidth but has the same effect)
Want to hear more from Chris on detection and response? Check out his recent presentation on Outsourcing Endpoint Security.
We go through this continuously at Red Canary. In fact, given this concept, you could say that Red Canary’s entire reason for existence is to help companies increase their response bandwidth . . . so that they can do better detection . . . so that they can make their security better. This means that we are constantly monitoring our own response bandwidth. When we see the volume of potentially threatening events (our equivalent of an alert) nearing our bandwidth, we start looking at ways to increase that bandwidth. Our process is a mix of the three methods mentioned above:
- Analyze our detectors to determine if there are some that should be turned off or tuned to reduce volume
- Optimize our analyst views or processes to reduce event confirmation time
- Hire more analysts
 The great thing about this approach is that whenever we have an idea for a new detection technique, we assess it from the perspective of our ability to handle the event volume and think about how we increase our bandwidth to handle it. At the end of the day, the more bandwidth we can create, the more detection we can do for our customers, and the better we make their security.
The great thing about this approach is that whenever we have an idea for a new detection technique, we assess it from the perspective of our ability to handle the event volume and think about how we increase our bandwidth to handle it. At the end of the day, the more bandwidth we can create, the more detection we can do for our customers, and the better we make their security.
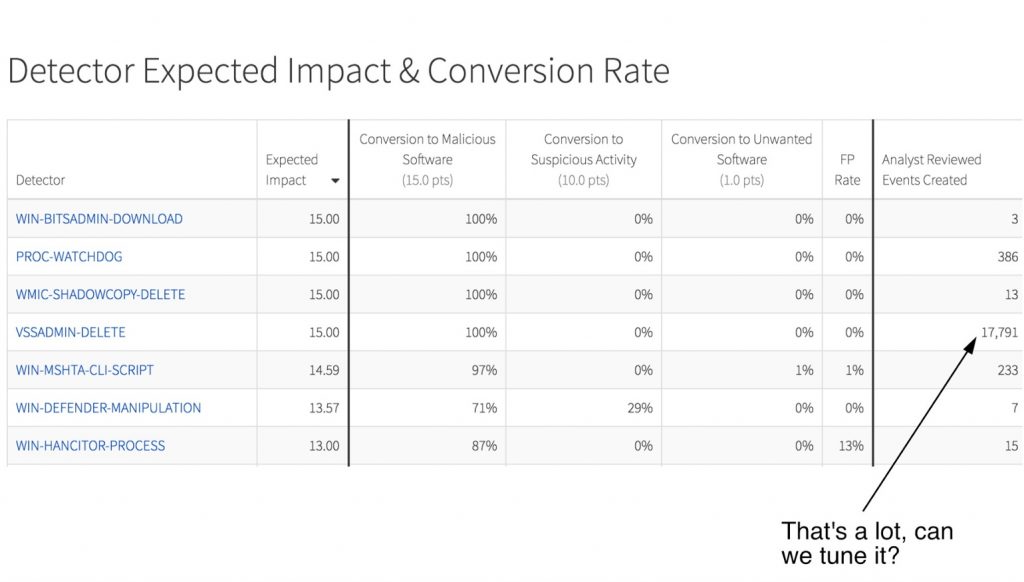
As a parting word, if you are in the process of trying to improve your endpoint detection I would strongly encourage you to analyze your response bandwidth. We constantly are talking with companies that purchased an EDR tool but didn’t account for the work the tooling requires. To give you an idea, here is a sample of our monthly impact report that details that amount of work that goes into a fully built out EDR capability.
How have you found success with increasing your response bandwidth? Share your thoughts or questions with me on Twitter (@crothe).

Related Articles
How AI will affect the malware ecosystem and what it means for defenders
How AI will affect the malware ecosystem and what it means for defenders
Why Taylor Swift fans should work in cybersecurity