
Scanning files for known malicious patterns has long been a technique for identifying malware on a computer’s filesystem. However, adversaries can easily subvert this with simple malware techniques (packers, obfuscators, etc.).
In this blog post, we’ll be taking a look at how Process Memory Integrity (PMI) techniques aid in detecting fileless or obfuscated malware on Linux systems. We’ll examine how pattern-matching tools can be used to target system memory with minimal impact on the performance of the system.
This is the second post of the Process Memory Integrity blog series, focusing on how these techniques are applied in a Linux environment. If you’re unfamiliar with PMI, give our introductory post a read.
Telltale malware patterns
Like any form of software, malware often contains byte or string patterns that make them uniquely identifiable. When a combination of these patterns are present in a file, it is a good indication that the system has been compromised. So what constitutes a malicious pattern? Various types of strings are considered to be low-hanging fruit:
- Domain names or IP addresses associated with known command and control (C2) servers
- File paths that are unlikely to be found in other software
- Function and variable symbols, artifacts of the malware code itself, left in the binary
- Environment variables used by the program
In addition to strings, the code itself can be used as an identifiable source. As we’ll explore later, some malware families reuse public projects or libraries, which often contain their own unique patterns.
Why scan memory for these patterns? Fileless malware is not subject to file-based scanning, nor to hash-based allowlisting/denylisting. In addition, it is very common for malware to use packing programs like UPX, gzexe, and gscript. While it’s fairly easy for malicious programs to disguise themselves while on disk, it is much more challenging to hide the artifacts they leave in memory during execution. Scanning process memory for these patterns allows us to pick up where file-based scanners fall short.
YARA (“a pattern-matching swiss knife for malware researchers“) has been heavily adopted by the security community as the go-to pattern-matching tool. While it is most commonly used to search for malicious patterns in files, YARA also supports targeting process memory. To demonstrate this feature, we wrote a basic Java program containing a few string patterns that YARA will search for:
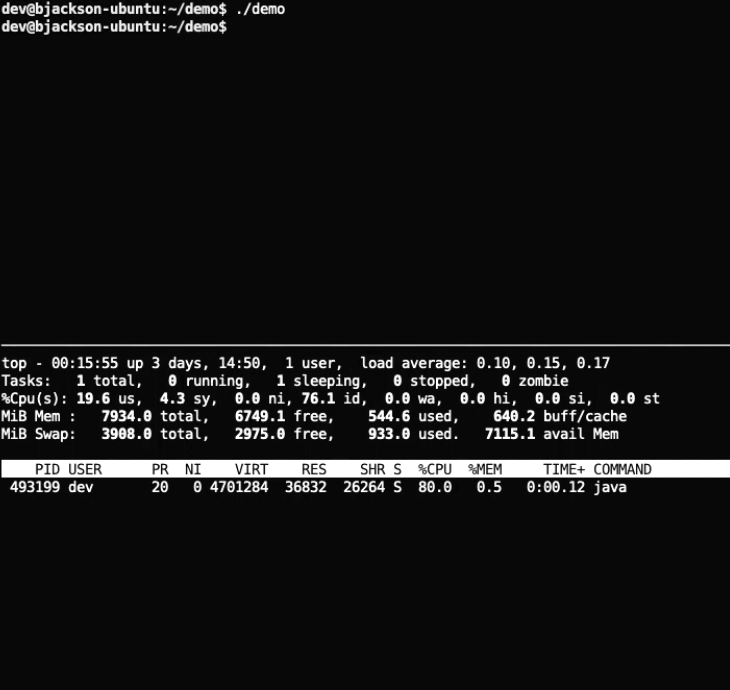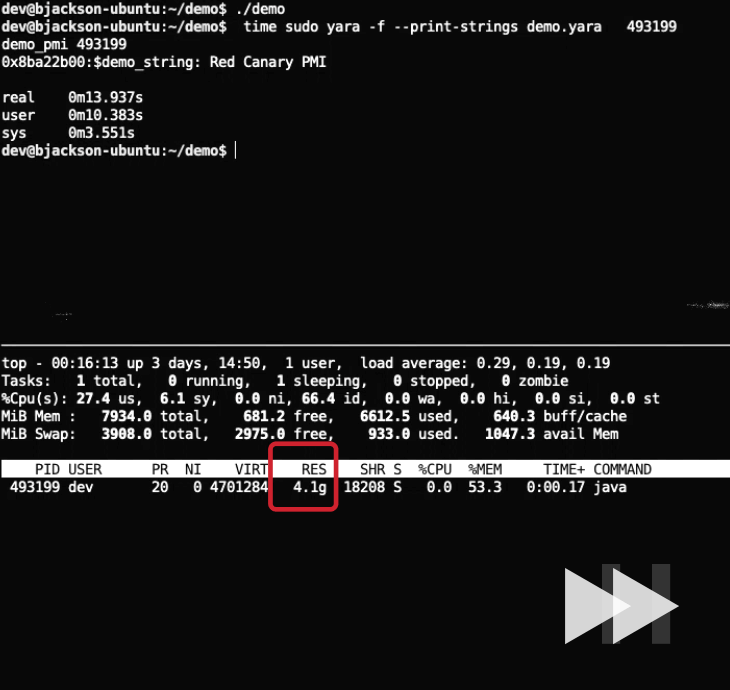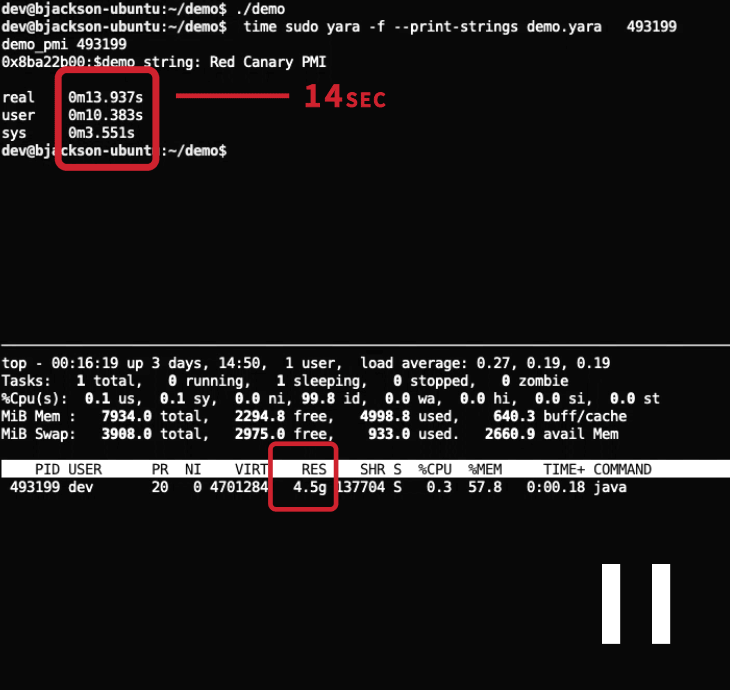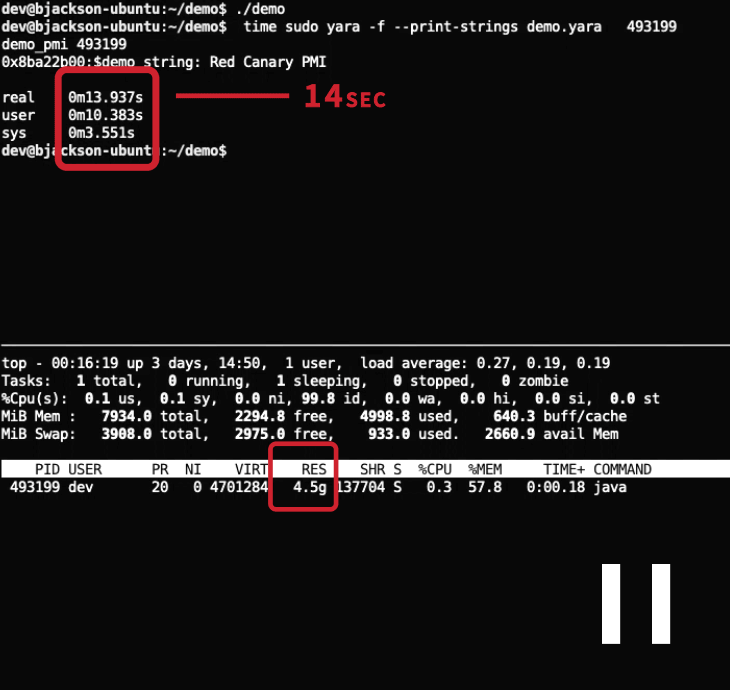
As highlighted in the GIF, as soon as YARA initiates the scanning, the program’s resident memory use spikes. This is an unfortunate side effect of YARA’s implementation of memory scanning. Processes rarely fill up their virtual address space; only the pages that have been used, read from or written to can become resident. On Linux, reading from non-resident pages forces them to become resident, which may lead to resource starvation. Below is an example of the resident pages of a process after scanning with YARA:
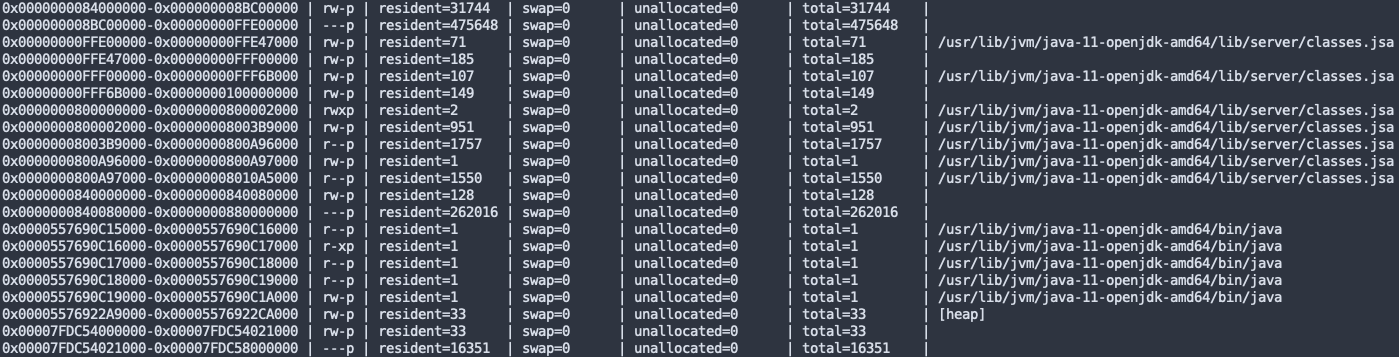
To avoid these inefficiencies, we implemented our own memory scanner with the help of YARA’s rule engine. By carefully targeting pages already resident in memory, we’re able to reduce the memory and CPU footprints. Here is a demonstration of our memory scanner, using the same YARA rule and Java program:

After running our scanner, you can see that most pages remain unallocated:
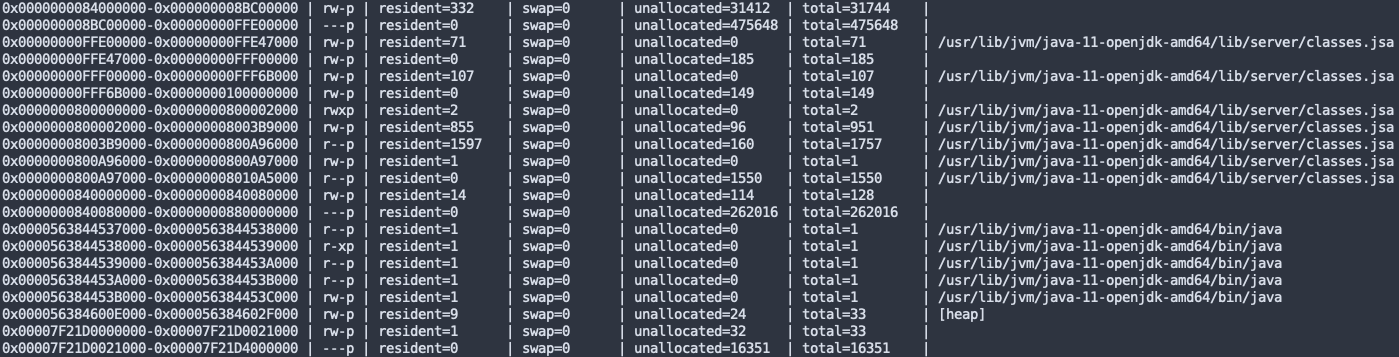
With some consideration to how Linux manages memory, we’re able to minimize the impact on performance. Many more considerations exist, but these are the most noticeable from a system administration perspective.
Case study: gobfuscate
In late 2020, a malware sample named “Blackrota” was unveiled to be a Go implementation of the infamous Cobalt Strike Beacon. Go itself adds a layer of obfuscation, but the authors went one step further and compiled it with a tool, gobfuscate, that explicitly hides strings, package paths, and other metadata. However, tools like this tend to be uniquely identifiable.
When compiling an application with gobfuscate, each string literal gets replaced with its own inline “de-obfuscation” function that performs an XOR operation against two buffers. The result of the function is the original plaintext string. Here’s how that function might look like written in Go:
var exampleString = (func() string { mask := []byte("\x21\x0f\xC7\xbb\x81\x86\x39\xac\x48\xa4") maskedStr := []byte("\x73\x6a\xa3\x9b\xc2\xe7\x57\xcd\x3a\xdd") res := make([]byte, 10) for i, m := range mask { res[i] = m ^ maskedStr[i] } return string(res) }())
This function is a great candidate for a YARA rule; it exists for each unique string, is not written by a human, and takes no input. Below shows the disassembly for the de-obfuscation function of the string, “Red Canary”:
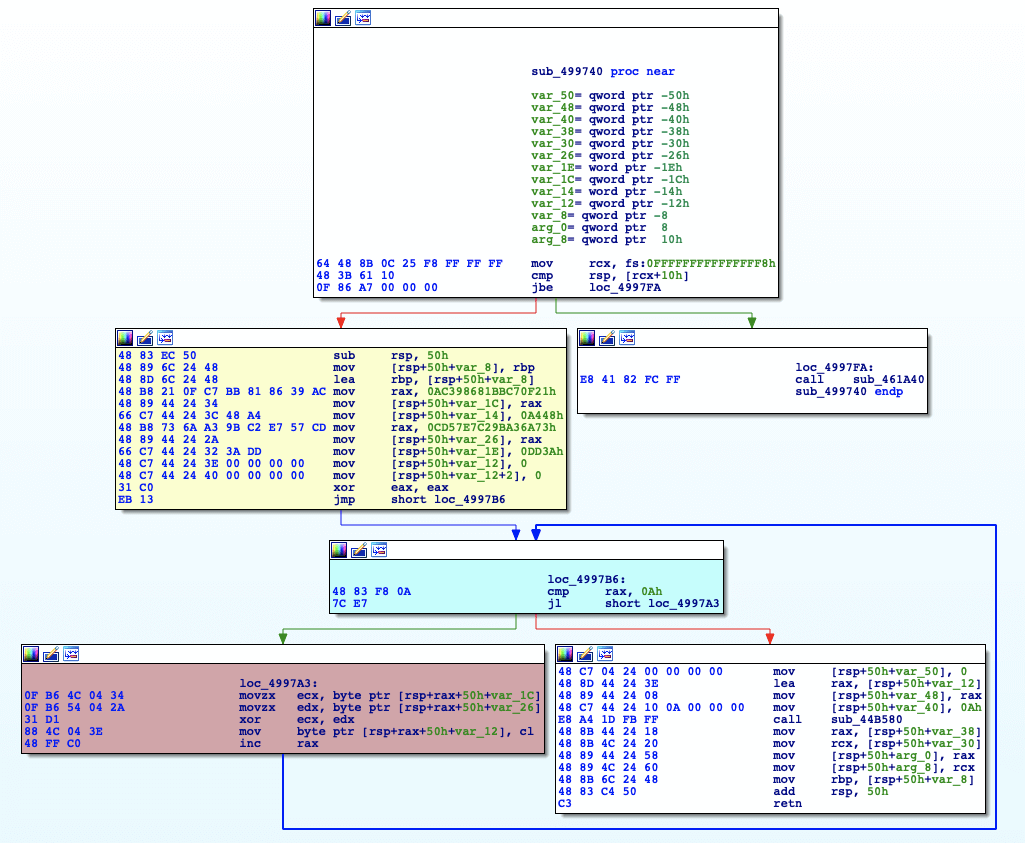
Comparing the string de-obfuscation functions within the same binary, there is not a lot of deviation in instructions and the overall control-flow graph. Major differences occur in the yellow block, which copies the values of the XOR key and XOR’ed string to the stack. These blocks are unique per string. The blue block (loop condition), and red block (XOR operation) are generally the same between functions, minus stack offsets and register selection.
Because this de-obfuscation function has basic blocks that are consistent across variations, we should be able to create a rule with minimal false positives. In order to capture all instances of this function, we need to replace bytes containing memory offsets with wildcards or jumps. The objective of the rule is to match the XOR operation, loop condition, and epilogue of the function, since the ordering of instructions is somewhat unique:
$x64_string_deobfuscate = { (76 | 0F 86 ) [1 - 8] // jbe loc_499484 [10 - 150] // Skip over mask/maskStr initialization // < XOR operation > [0 - 1] 0F B6 [2 - 6] // mov ecx, byte ptr[mask + index] [0 - 1] 0F B6 [2 - 6] // mov edx, byte ptr[maskStr + index] [0 - 1] 31 (C? | D? | F?) // xor ecx, edx [0 - 1] 88 [1-8] // mov [res + index], cl [0 - 1] FF C? // inc rax [0 - 6] // no-op // < Loop condition > [0 - 1] (3D | 83 | 81) [1 - 6] // cmp rax, len(res) (7C | 0F 8C ) [0 - 6] // jl loc_49942C [0 - 64] // skip `slicebytetostring` args E8 [0 - 8] // call to `slicebytetostring` [0 - 64] // skip return value staging c3 // retn }
There are few gotchas to look out for when using machine code patterns:
- Register and offset exclusion
- Ensuring code generation is similar across different configurations
- Targeting non-turbulent functions (handwritten assembly, tool chain-generated code, etc.)
Conclusion
With this approach we can focus on code that is commonly used maliciously without having to worry about the innumerable forms of file-based obfuscation techniques. This has enabled us to easily detect all forms of bitcoin miners, no matter how they are packed, distributed, or are executed.
In our next blog post, we’ll be taking a deeper look into Process Memory Integrity techniques that behaviorally detect code injection. Stay tuned!
Related Articles
eBPFmon: A new tool for exploring and interacting with eBPF applications