
In the words of Principal Software Engineer Brian Davis:
“What the engineering team does at Red Canary is very easy.”
<pause for dramatic effect>
“…the scale at which we do it is very hard.”
When I was hired at Red Canary three years ago as a senior software engineer (a long time in both dog and software engineer years), it was immediately obvious to me that the opportunity to work on this scale of data only exists at a very few companies.
I was lucky enough to join what eventually became Red Canary’s Integrations Team, which is responsible for the ingestion of software-as-a-service (SaaS), platform-as-a-service (PaaS), and cloud provider logs, alerts, and telemetry. I was also fortunate to find myself in the hands of a great engineering manager surrounded by amazing software engineers. In retrospect, perhaps this was not so much luck, but rather the byproduct of the engineering excellence Red Canary tries to facilitate.
To illustrate this excellence, I’m going to walk through how we recently created Red Canary’s integration for Google Cloud Platform (GCP).
Addressing the GCP gap
It all starts with the product people (our product managers), and as product people are wont to do, they engage with our customers. They learn what our customers are doing, how they are doing it, and the security concerns keeping them up at night. This allows Red Canary to build products that protect our customers, give them confidence to focus on their core business functions, and not worry endlessly about cyber threats. It turns out that our customers were worried about their cloud resources in GCP. We had recently released integrations allowing us to protect cloud resources in AWS and Azure, but we did not yet have coverage in GCP. And our customers had noticed.
To cover GCP, we needed to monitor the control plane telemetry: logs related to the creation, modification, and destruction of cloud-based resources via API calls. We also needed to monitor user and service account actions regarding data access, login, and permissions within the platform, as identity can be viewed as the security perimeter of the cloud. In order to do this, we needed to have visibility into the platform’s logs, look for suspicious activities, and correlate them to behaviors that may be a threat. Therefore, first and foremost we needed to figure out how GCP processes, transmits, and stores the information, then get it into our system.
 For a detailed look at how Red Canary ingests millions of cloud telemetry logs a day, check out our Shrinking the haystack blog series.
For a detailed look at how Red Canary ingests millions of cloud telemetry logs a day, check out our Shrinking the haystack blog series.
Not all cloud providers are created equal
While we were just getting started with GCP, Red Canary had plenty of experience with integrating Azure and AWS to build upon. However, we needed to make sure that our integration followed Google Cloud best practices and not AWS best practices hamfisted into Google Cloud. Red Canary provided me with the resources to blitz through the GCP Associate Cloud Engineer Certification exam in order to learn about how the platform operates, what it offers, and in particular to start digging into the logging resources and functionality. Our team quickly learned that GCP, Azure, and AWS all do things a little differently. They use different names for the same things, or charge a fraction of a penny more or less for the same type of cloud resource. However, because every cloud provider is implemented vastly differently behind the scenes, accessing cloud control plane logs tends to vary significantly between providers, which poses huge engineering challenges at scale.
We needed to make sure that our integration followed Google Cloud best practices and not AWS best practices hamfisted into Google Cloud.
Red Canary’s preferred process for cloud platform ingestion involves pulling large files containing thousands of logs out of a storage mechanism (like an S3 bucket) and into Red Canary’s environment via SNS topics and SQS queues.
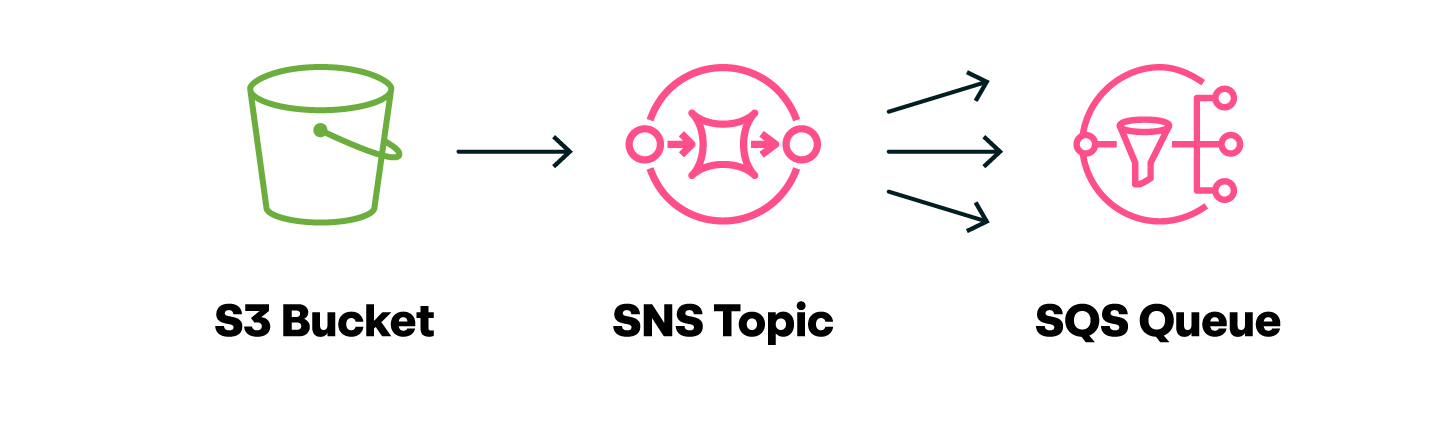
Most cloud providers do some sort of batching or grouping of the logs for you: AWS will bundle and write them to a S3 bucket, Azure will bundle and write them to a bucket storage account, or push them to an Azure Event Hub, and then batch them. GCP has a batching capability that can write the logs into a bucket, however it delays log transmission by up to an hour. Waiting an hour for telemetry to arrive can make for a bad day with a malicious actor being unkind in your cloud environment.
That was the bad news. The good news, though, is that GCP has the ability to output audit logs in real time, but only as a flood of individual messages. This left us with a significant engineering challenge to overcome: how can we tolerate this torrent of teeny tiny data?
Objectives for the GCP integration
Through our initial investigation and understanding of GCP, we were able to nail down what our ingestion integration needed to do:
- Be secure, scalable, reliable, and timely
- Consume potentially billions of tiny messages per day from GCP’s logging system
- Provide customers with an easy way to connect GCP to Red Canary
- Allow us to monitor the ingestion system’s health both on the Google Cloud Platform and Red Canary side of the fence
- Keep the cost of the GCP integration low enough that our CFO didn’t come and yell at us (much)
Finding the right ingestion tool
The first time someone had to consume billions of messages I’m sure it was a daunting task, however, technologies like Apache Kafka have largely solved that problem. Our system has deliberately avoided (and actually abandoned) Kafka in the past, as it became unwieldy to manage at massive scale when we were not just consuming messages, but messages from many different telemetry sources, for many different customers, with many different schemas. The aim for our solution was to be as simplistic—and cost effective for both us and our customers—as we could possibly be.
To this end, we wanted to avoid spinning up resources in our customer environments, because that would be really difficult to manage long term (not to mention a bit weird). Additionally, we were trying to keep our footprint in Google Cloud minimal; not because we don’t like Google Cloud. Rather, it would be yet-another-thing that we have to manage and keep track of. (As a side note: Because of my work on this project, GCP has become my quick go-to cloud pocket knife for simple tasks.)
The aim for our solution was to be as simplistic—and cost effective for both us and our customers—as we could possibly be.
We considered writing and deploying our own small service on our infrastructure, which would consume GCP’s individual messages, parse them, batch them into line delimited JSON, and then push them into our system. We have followed this pattern in the past. This seemed like something that Kubernetes would love to handle, but with potentially thousands of Google integrations, on thousands of pods, sending billions of messages, it’s something we did not want to have to maintain in Kubernetes. Bringing a nuclear weapon to a knife fight is not necessary, and Kubernetes problems at 2AM are not fun (in all fairness, Kubernetes problems any time of day are not fun either). More importantly, however, is the fact that our system is based on reads and writes to S3 in between Kubernetes components—and billions of small-file read and writes in S3 can become cost prohibitive really quickly.
Next, we looked at using Azure Functions or AWS Lambda to consume the messages for us, parse them, and store them in a system for batching. This is a pretty common solution that most cloud providers suggest to address this type of problem. But our back-of-the-envelope math determined that invoking billions of serverless functions would likely fail the requirement of “don’t give the CFO a reason to yell at us,” and we didn’t really want to fully fund the AWS employee’s polo team.
Because every cloud provider is implemented vastly differently behind the scenes, accessing cloud control plane logs tends to vary significantly between providers, which poses huge engineering challenges at scale.
In our search, we also came across Amazon Data Firehose, a delivery system for real time data streaming normally found on the output of an Amazon Kinesis setup. However, no one at Red Canary was an expert in Firehose, it was not in use in our system at the time, and we needed to know that it was going to be robust and not a nightmare to implement and maintain at scale (again, all of these solutions can be really easy…until you try them at scale).
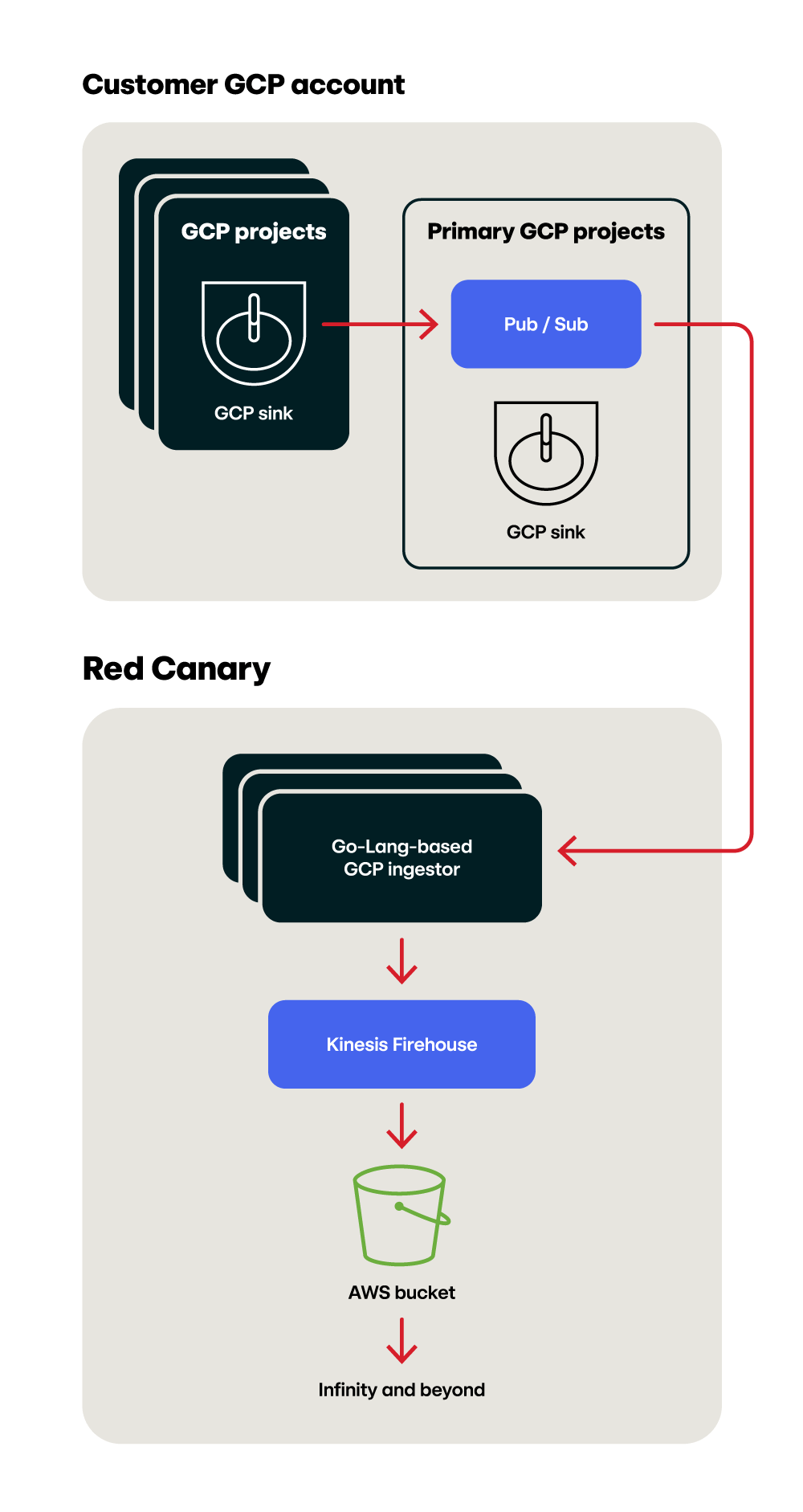
The more we looked at Amazon Data Firehose, the more it looked like the right tool for the job. A managed AWS service that batches billions of messages, either by volume or time, Firehose can dynamically partition messages, allowing us to keep customers’ data separate. We built out a proof of concept, tested it, and saw data landing in our system in the correct places. The cost was low, the throughput scalable, and we did not have to worry about managing our own infrastructure.
With a successful proof of concept and buy-in from all concerned parties, even the Brian Davis, I designed the system from stem to stern, keeping all of our objectives in mind and making sure they were all addressed.
Designing, delegating, and delivering
Throughout the entire process, my engineering manager, the staff engineers, principal engineers, and our AWS support staff all rallied around me, answered my questions, lent hands when I was struggling, and pointed out when I was about to shoot myself in the foot. I decomposed the design into tracks of work that could be executed in parallel. Each deliverable part of code was presented to and reviewed by the team. Through this I estimated a total development time, identified parallel tracks of work, and assigned engineers to tackle the work. Everything converged at end-to-end testing, we wrote solid documentation, and onboarded our technical customer-facing teams, all with an extensive support network to coach me along the way.
Red Canary’s GCP integration completed on schedule and we onboarded our first early access customers to our MDR for Cloud with GCP in early February 2024, just in time for me to disappear for 8 weeks to welcome my newborn daughter to the flock.
Eight weeks later when I returned, some software engineering years had transpired, but everything was going well. We’d onboarded customers, the processes were smooth, and any discovered bugs, scalability hurdles, and technical debt had been ironed out.
It was a wonderful feeling to disappear from a project I’d been leading, come back and everything was solid or improved.
The end result
Integrating GCP log ingest into our system introduced an invaluable new technology into our stack; Amazon Data Firehose allows us to ingest billions of individual GCP messages in real time, while dynamically parsing the messages to keep our customers’ data secure and separate. It puts the batched messages in the format we export at the beginning of our detection engine. To that end, we’ve successfully introduced Data Firehose into other parts of our system as well.
Since our initial capability rollout, we’ve onboarded more Google Cloud customers and are consuming roughly 200 million telemetry records per day. It’s a fraction of the nearly 1 petabyte we consume daily, across all of our integrations, but it’s satisfying to see it streaming seamlessly into our system. It’s even more satisfying to see us using it to stop adversary activity in our customers’ cloud environments.
A bedrock at Red Canary is fostering a culture of engineering excellence that aims to build quality products for our customers. It allows our engineers to operate within guard rails that keep our systems stable under incredible load, while still learning, experimenting, occasionally failing (safely), and finding or building the right tools for the tasks at hand. Designing and implementing Red Canary’s GCP integration helped me gain skills in areas where I wanted to grow—skills I now get to pass on to new team members.
Related Articles
The million-dollar front door and the tailgater: Why strong auth could fail at SaaS session integrity