
Red Canary has been working with AI workflows for a while now. With how quickly technology is progressing in the AI space, we wanted to shine light on one of the latest and most popular advances, the Model Context Protocol (MCP).
This blog will serve as a guide to better understand the security implications of MCP and agentic AI workflows. We’ll discuss general principles, some of the latest threats impacting the space, and steps you can take to safely introduce MCP servers into your workflows.
What is the Model Context Protocol?
MCP is a protocol, developed by Anthropic, that facilitates the communication between large language models (LLM) and tools to standardize how your AI workflows interact with resources. It’s been described as a “USB-C port for your AI applications.” The two main components of MCP are clients and servers. Clients provide the interaction between the LLM, user, and servers. Servers hold tools which can connect to any resource you would like. The figure below is adapted from Anthropic’s documentation demonstrating how clients, servers and resources interact.
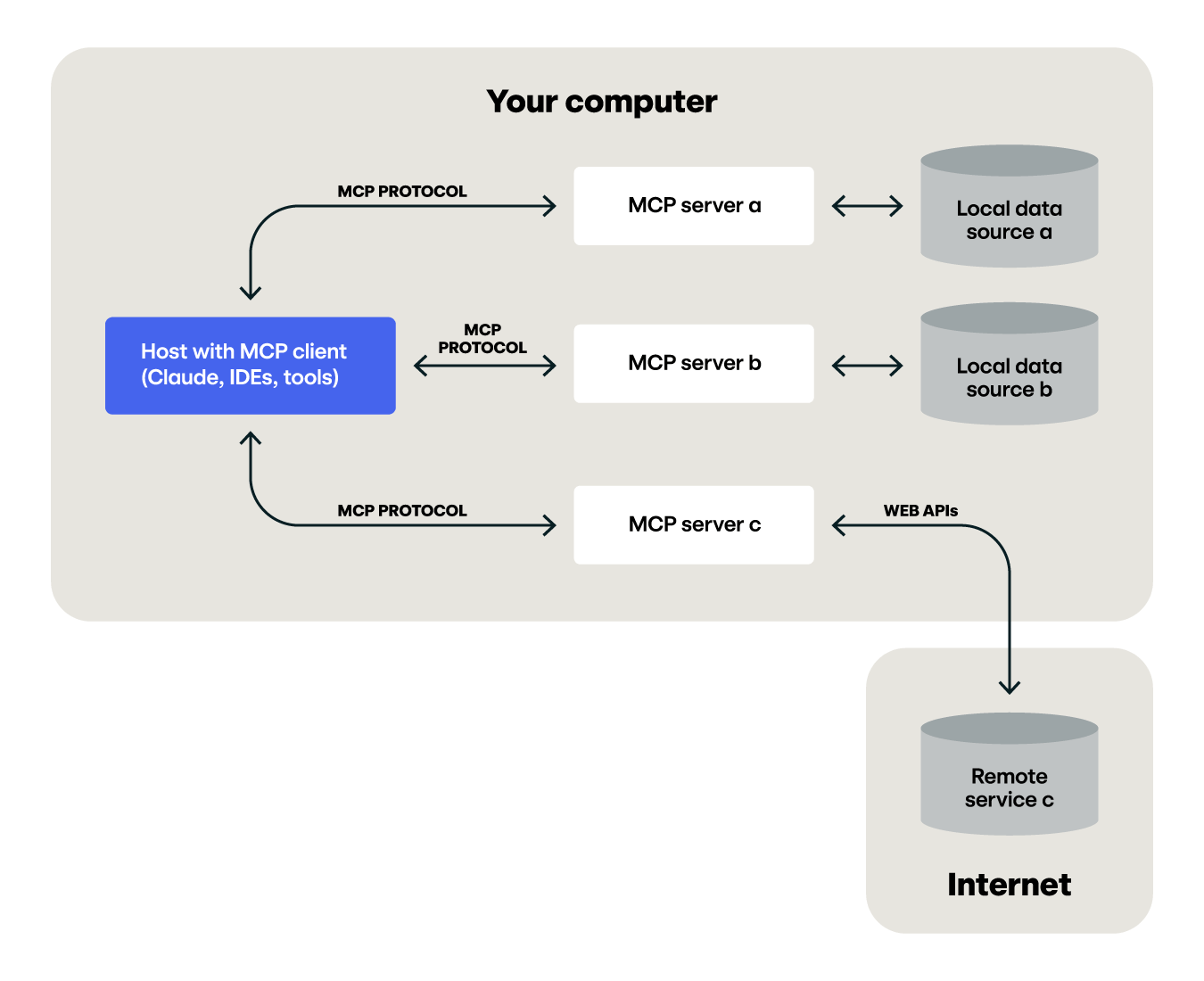
MCP servers can be either hosted locally or remotely. In local configurations, you can pass commands between clients and servers using the command line stdio. For remotely hosted servers, Streamable HTTP is the recommended transport mechanism. Overall, the transport protocols leverage JSON-RPC 2.0, so there are several options for coding your own transports for requests and responses.
The true power of MCP servers comes from the tools and capabilities they host. Without tools, the MCP server provides no functionality that the LLM can leverage. MCP supports software development kits (SDK) for several languages such as Python, Ruby, TypeScript, C#, Swift, and others. These tools allow the model to perform nearly boundless activity and are only confined to what the developer creates and the level of access you grant.
The true power of MCP servers comes from the tools and capabilities they host.
When you issue a prompt to the LLM, the model will attempt to reason about the best method to solve whatever task you have defined. It will query available MCP servers and their associated tools, then it will make a decision on what tool is best suited for the task. This is a boon for AI agentic workflows but it also comes at a very large risk for organizations. In the immortal words of Uncle Ben: “With great power comes great responsibility.”
Security implications of MCP
At its core, MCP simply allows developers to facilitate AI agents to execute code. Securing MCP servers shares fundamental similarities with securing any code execution environment. Just as Python, PowerShell, or any other language can be used to perform a wide range of actions on a system—including potentially harmful ones if not properly secured—MCP enables AI agents to execute code and interact with various resources, presenting comparable risks.
MCP by itself does not include security mechanisms. The absence of built-in security is not a defect, but instead emphasizes the expectation that developers will implement standard security best practices. MCP enables powerful capabilities through tool execution, and with this functionality comes important security and trust considerations that all developers must carefully address, specifically regarding user consent, data privacy, tool safety, and LLM sampling controls.
The absence of built-in security in MCP is not a defect, but instead emphasizes the expectation that developers will implement standard security best practices.
Developers are consistently entrusted with securing applications and code, regardless of the environment or language, and MCP is simply another context where well-established principles like input validation, access control, least privilege, and thorough monitoring must be rigorously applied to mitigate security risks. While MCP does not enforce these principles at the protocol level, developers should build robust consent and authorization flows, provide clear security documentation, implement appropriate access controls, and follow security best practices such as the principle of least privilege.
Overall, MCP introduces some unique risks due to the automated nature of allowing LLMs to read, modify or execute arbitrary code granted through tool access. Security teams must understand these risks and work with developers to collaboratively build capabilities that are effective and secure.
Let’s talk through some specific security considerations for MCP servers and types of telemetry you could leverage for detection and monitoring.
Data exposure
Data exposure is a significant concern when deploying MCP servers, primarily because these servers enable AI agents to interact with a wide range of resources. By granting tools the ability to access diverse data sources, organizations risk accidentally cross-contaminating sensitive information with public data. If developers have access to both types of resources and tool usage is not adequately restricted, AI agents could inadvertently pull and combine data from various origins. This lack of isolation could lead to confidential details being merged with public data, potentially resulting in leaks or breaches of sensitive information.
Furthermore, if single sign-on (SSO) and short-term access keys are not implemented rigorously, or if long-term keys are used, organizations face the risk of credential leakage. AI agents using weak security measures could expose credentials, which adversaries could harvest.
Model hijacking
Model hijacking within MCP server workflows is particularly a risk when tools can access public content without stringent execution controls. In such scenarios, a malicious actor can strategically place a manipulated prompt in a publicly accessible location. The AI agent, upon accessing this content, may misinterpret the malicious prompt as a legitimate instruction due to a lack of robust validation mechanisms. This misinterpretation can lead the agent to execute unintended commands or access data resources that are beyond its intended current scope.
The consequences of a successful model hijacking attack can be severe. For instance, the hijacked agent could be tricked into exfiltrating sensitive data, modifying critical system configurations, or initiating disruptive actions. This risk is magnified if the agent possesses elevated privileges or connections to numerous systems and data stores. Here, the adversary effectively leverages the inherent trust relationship between the agent and the MCP server, using it as a vector to perform harmful activities within the trusted environment.
Mitigating the risks of model hijacking is similar to standard security practices around securing any other types of identities. Strict tool execution controls are important, ensuring that the AI agent only performs authorized actions based on verified inputs. Input validation is essential to filter out malicious or manipulated prompts before they can be processed.
Lessons learned: A case study
As we’ve written about before, investigating identity and cloud threats is challenging due the high requirement of building contextual understanding to make a determination if any given threat is simply user behavior or malicious activity. To help alleviate analyst workloads, I built an MCP server that helps investigate AWS alerts in OpenSearch.
A developer’s first instinct might be to write a tool that allows a model to create any arbitrary OpenSearch query that would be helpful for the given task. However, I found that not only did this reduce the quality of results, but also introduced several security and production risks. It could lead to data cross contamination or cluster overload if the model attempted to query very large amounts of data. Instead of building a single tool to query our data, I built several tools that were tailored to specific tasks.
One tool found related events given certain key fields like userIdentity.arn and a customer identifier. I also limited the inputs to exit if it detected the model trying to query outside of certain time bounds or number of results. Below is sample code from a tool demonstrating how to guide model usage and limit impacts.
if not (0 < maxResults <= 1000): # Max OpenSearch window size is 10000
return [{"error": "maxResults must be between 1 and 1000."}]
if not (0 < timeWindowMinutes <= 1440): # Max 24 hours
return [{"error": "timeWindowMinutes must be positive and reasonable (e.g., <= 1440)."}]
query_body = {
"query": {"bool": {"must": [], "filter": []}},
"size": maxResults,
"sort": [{"eventTime": "asc"}]
}
must_clauses = query_body["query"]["bool"]["must"]
filter_clauses = query_body["query"]["bool"]["filter"]
must_clauses.append({"term": {"<customerIdentifiderField>": <customerIdentifiderValue>}})
must_clauses.append({"term": {"userIdentity.arn.keyword": <userIdentity.arn>}})
identity_should_clauses = []
if accessKeyId:
identity_should_clauses.append({"term": {"userIdentity.accessKeyId.keyword": accessKeyId}})
if identity_should_clauses:
must_clauses.append({"bool": {"should": identity_should_clauses, "minimum_should_match": 1}})
I leverage the model’s natural language processing to simply parse CloudTrail events and then plug in certain key values rather than giving it full access to create a query without bounds.
While this specific capability could be suited to more traditional security practices by parsing the fields yourself, by leveraging reasoning models, the agent will continue to iterate over the data with various fields to find relationships in a dynamic way that would be very difficult with bespoke algorithms.
Telemetry and security
Overall, our goal in detecting malicious MCP interactions is to correlate prompt to execution. Building this chain of activity can be extremely challenging. As MCP and AI agents have no built in identifiers, they interact with resources in the same way a normal user does. This is a benefit as we can leverage our existing tooling to track malicious AI agent abuse. However, these workflows can move extremely quickly. AI agents combine the flexibility of a user with the speed of automation, making it tricky to monitor and respond quickly enough to limit compromise.
Telemetry for identifying MCP execution largely comes from these main sources:
- endpoints
- identity/cloud control plane
- application logs
- model proxy logs
- prompt logging
Endpoint telemetry for both MCP clients and servers can be helpful in detecting malicious command execution or file manipulations. Identity and cloud control plane telemetry are also important if you build workflows that are meant to interact with continuous integration and continuous delivery (CI/CD) pipelines or otherwise enable MCP servers to access cloud resources.
Identity logs, such as those provided by Okta, AWS IAM, or Entra ID are especially helpful for tracking when and where AI agents leverage authentication to access resources. However, correlating these logs back to MCP activity can be difficult unless specific identifiers, such as user agents are built into the MCP implementation or access keys are explicitly created for AI agent usage. Without these measures, there might be no clear indicators that an AI agent, rather than a human, is performing the data access, making detection and prevention difficult.
Application logs can provide the most robust source of telemetry for monitoring and detecting MCP server abuse. Since MCP is an open protocol, you can log anything you would like within an MCP server. Standardizing logging to common formats, such as syslog, is critical to facilitating the integration with existing security workflows. Application logs can provide the most detailed information about what an agent is performing and any errors it is encountering.
Application logs can provide the most robust source of telemetry for monitoring and detecting MCP server abuse.
Finally, prompt monitoring can be essential for detecting malicious prompts intended to hijack resources. It is also critical for building the entire narrative of potential compromise as it allows us to point to the moment any workflow might have moved outside its intended bounds. A growing domain in this space is model proxies. These services provide a method of routing requests to various models so the user can decide which model they would like to leverage. We have previously discussed the benefits of proxy logging, as it provides excellent insight into model behaviors and prompt analysis.
Securing MCP servers
Overall, MCP servers should be approached with the same security mindset as any untrusted application. Their reliance on good coding practices means that rigorous error handling, comprehensive application logging, and thorough prompt verification are essential. The open nature of the MCP protocol, coupled with the rapid pace at which AI agents operate, necessitates the development of highly secure MCP implementations to mitigate risks. Just as with any application, the security and integrity of MCP servers hinge on vigilant monitoring and proactive defense measures to safeguard against potential vulnerabilities and exploits.
Related Articles
Train, triage, repeat: The AI agent changing how we fight phishing
The dual-use dilemma: Rethinking detection for remote access tool abuse
The dual-use dilemma: Rethinking detection for remote access tool abuse
Investigating suspicious AI workflows in Microsoft Entra Agent ID: Assistive agents