
Identity and access management (IAM) has become one of the most important components of security operations as organizations have moved their infrastructure to the cloud and adopted cloud-hosted SaaS applications. Fortunately, there’s a bunch of identity platforms that IT teams can use to provision access to cloud assets and SaaS applications, and they generate alerts and telemetry that are useful for security teams in their effort to identify anomalous or suspicious or potentially malicious logins.
Unfortunately, properly investigating alerts, making sense of identity logs, and identifying anomalies make for a tall order when users are logging in from different devices in different locations and different times.

Baselining normal against everything else
Determining what is anomalous starts with understanding what is normal—and then being able to detect or reliably find deviations from normal activity. Defenders have long leveraged the concept of baselining across network and endpoint investigations (obligatory reference to the SANS hunt evil poster).
Network baselining can include inputs like:
- port and protocol pairings
- the frequency of internal or external network connections
- the normal amount of information transiting the network
Establishing these patterns can help identify network spikes or abuse of normal protocols that are abnormal to that network—and thus might be malicious.
Similarly, endpoint baselining examines inputs like:
- typical processes
- process lineage
- command lines
- network connections
These patterns can aid in determining process abuse, enhancing the signal of what is abnormal for that endpoint, and again, aid in rooting out malicious endpoint behaviors.
The same principle applies to identities, and while baselining user behavior is complicated, it’s also achievable.
The importance of identity baselines
What sets identity baselines apart from network and endpoint baselines is the human aspect of the identity we are defending. Looking at an identity alert in a vacuum offers very little insight into whether the alert is triggered by activity within the normal patterns of behavior for that identity. In a global, hybrid, or fully remote workplace, a typical static baseline generalized across an entire organization and based on normal hours of operation from predictable locations or devices does not necessarily help defenders answer investigatory questions. Identity baselines must be dynamic and adaptable to each individual’s changing routine.
Some of the key components of identity baselines include login information like:
- locations
- IP addresses
- VPNs
- browsers
- device identifiers
- time
Security teams can use this information to ask and answer questions that will help them differentiate normal patterns of user login activity from suspicious or anomalous patterns that might indicate that adversaries have compromised an identity or account. However, identity-related logs can be voluminous, redundant, fragmented, and, ultimately, difficult to consume…for a human.
How Red Canary operationalizes user baselines
Red Canary’s identity baseline is created with an on-demand workflow, ensuring the most accurate and up to date information is presented to defenders. We collect telemetry from a wide array of identity platform logs and store them in our identity data lake. We start with a 30-day look back window for each identity, giving us the information we need to create a user baseline report for each individual identity. We then send this information through our identity workflow, where we enrich and process the information into two statistical aggregation data structures.
After enrichment, we have data structures that are informative on their own, but we leverage large language models (LLM) to create a summarized user baseline report that synthesizes critical context to help analysts sort normal login behavior from abnormal login behavior. We then use the data structures to deliver valuable context for investigations into patterns of user login behavior.
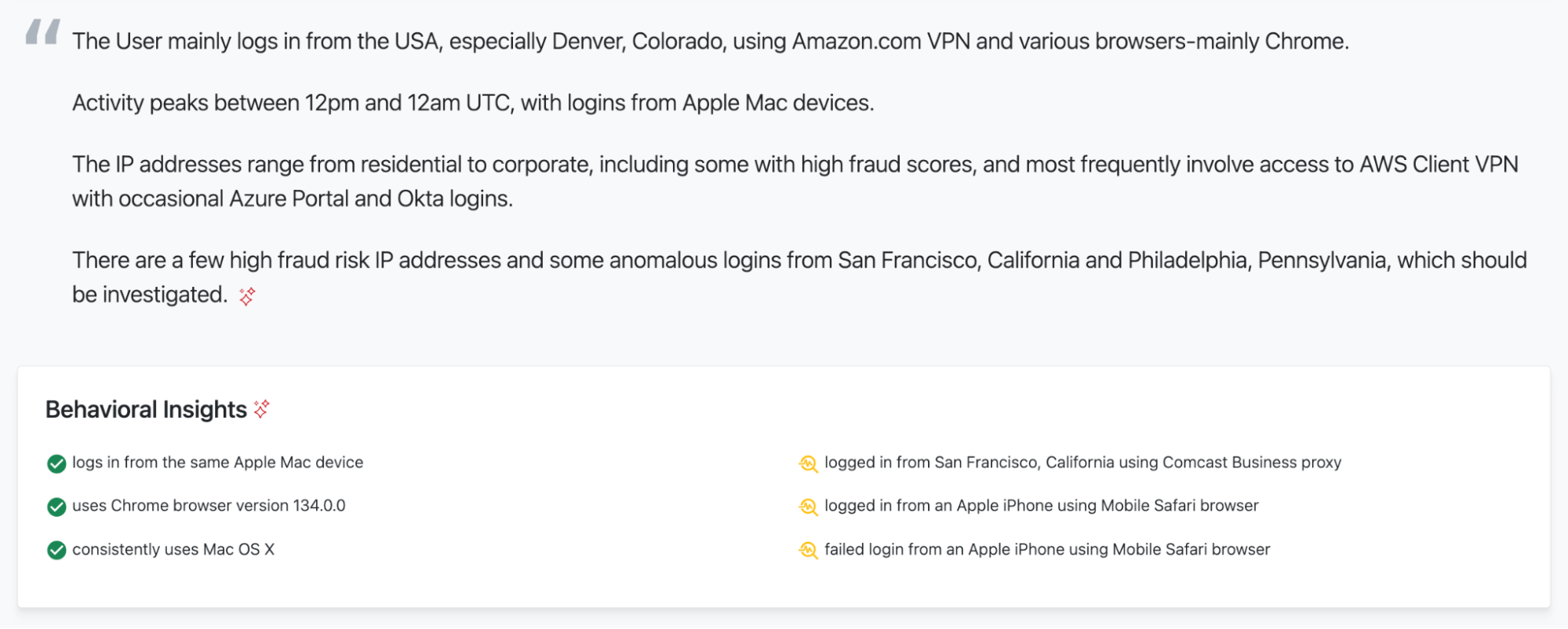
Example user baseline report in the Red Canary Portal
How do we create this baseline report?
The identity workflow we use to generate these reports can be broken out into four steps: data extraction, data enrichment, data processing, and data analysis.

Data extraction
We first extract 30 days worth of identity logs from our data lake that are related to the specific identity we’re investigating. The database returns a data structure containing the relevant fields we need for the workflow to streamline further data processing.
Data enrichment and processing
Using the Pandas Python data manipulation library, we further refine and clean the information extracted from the database. We separate log data as needed so that they’re stored in standalone fields in our data structure (called a “DataFrame” in Pandas). For example, we take the full content of a timestamp log and extract the specific day of the week or split geographic data into single fields for the city, state, and country.
Cleaning also serves the purpose of filling in any missing or incomplete data with the appropriate values. This enrichment and cleaning process is also known as “feature engineering,” which is crucial for the aggregations and machine learning we perform in the later steps of this workflow. Finally, we label each individual login (or login attempt) with a success or failure tag so that we can split our logins into ones that were successful and ones that failed.
We consider whether or not each login failed or succeeded to separate our dataset and display the count of unique values (see image below) for the key components of the baseline. The aggregations are then used to drive tables and graphs like the following:
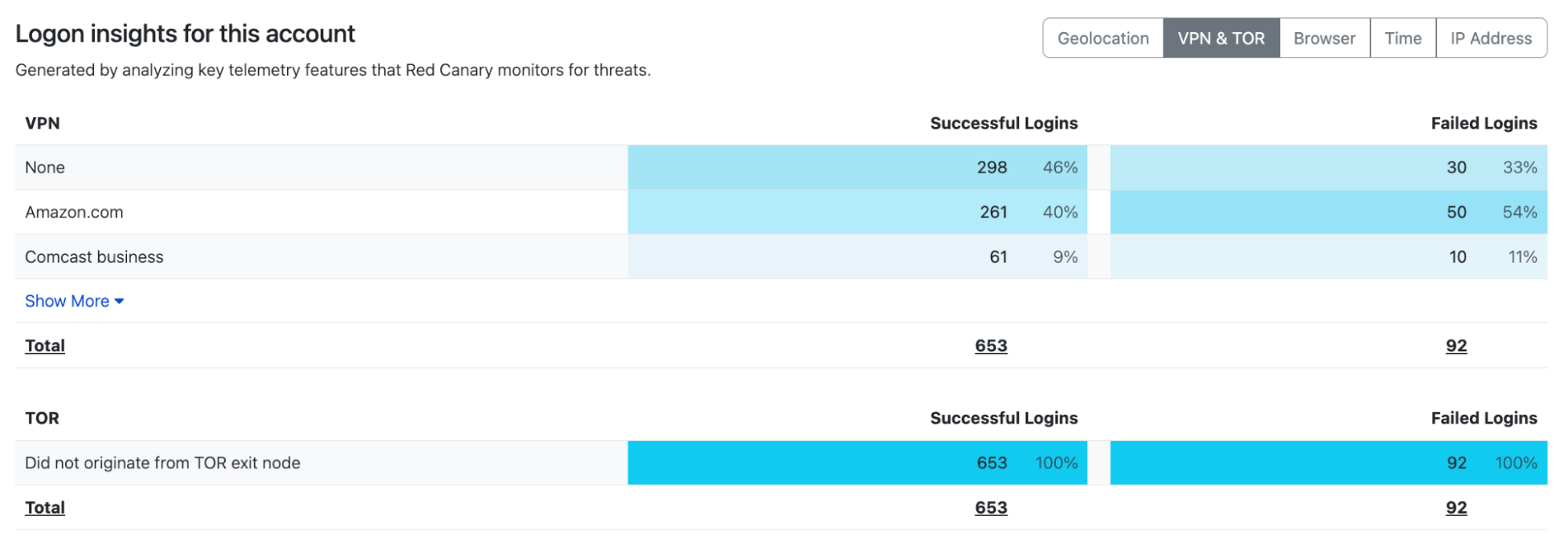 User login insights from the Red Canary Portal
User login insights from the Red Canary Portal
Data analysis
Now that we’ve cleaned and enriched the data, we can use it to establish and understand the trends within the baseline. Using Apriori analysis, we can identify the most frequent patterns of login behavior for a given identity and get a really good idea of what normal looks like.
We also rely on isolation forests to perform anomaly detection. An isolation forest is an unsupervised machine learning algorithm largely used for anomaly detection. Unsupervised machine learning is the best choice for this data set, as the algorithm can identify anomalies without any labels differentiating real login attempts from anomalous attempts, an otherwise impossible task at the identity level. The speed of this algorithm allows us to use it inline with our identity workflow.
The final benefit is that the algorithm will also adapt as new data is presented, meaning when a user gets a new device, we will initially flag logins from that new device as anomalous, but this will happen less often (and eventually not at all) as the user logs in more and more from that device.
Below is an example of the isolation forest model catching a Red Canary employee while they travel from their normal workplace to Dallas, Texas for a company event.
The User mainly logs in from the USA, especially Denver, Colorado, using various VPNs including Poly Zero Touch Provisioning and Amazon.com, and various browsers-mainly Chrome. Activity peaks between 2pm and 8pm UTC, with logins from Apple Mac devices. The IP addresses range from residential to corporate, including some with high fraud scores, and most frequently involve access to AWS Client VPN and Okta with occasional Azure and GitHub logins. There are a few high fraud risk IP addresses and some anomalous logins from Irving, Texas, which should be investigated.
Anomalous_behaviorlogged in from Irving, Texas using the lumen proxy, logged in from Denver, Colorado using the amazon.com vpn, failed login from an Apple iPhone in Denver, ColoradoCommon patterns: logs in from Denver without using a VPN, uses a Mac OS X device with Chrome browser, frequently logs in from an Apple Mac device
Each of the statistical aggregations, frequent user patterns and anomalies are insightful on their own. To achieve our single-pane view, we send all of this information to a custom-built AI agent to get text summaries for easy consumption in a natural language report.
We send these reports to our portal to allow for on-demand insights through both our report text and tables, allowing streamlined analysis for our analysts and a shared understanding with a customer-published identity threat.
Identity isn’t going anywhere
Gathering detailed telemetry from supported identity providers and leveraging AI agents to create human readable user-baseline reports has accelerated our ability to thoroughly and effectively investigate identity threats. This is super important because as we underscore in our recently published 2025 Threat Detection Report, identities are high priorities for adversaries as they seek access information contained within business-critical cloud assets and SaaS applications.
Baselining is also crucial because identity security products can create an overwhelming amount of noise with alerting that’s difficult to parse without a great deal of context. While identity alerting, logging, and telemetry have been available for many years, the advent of readily available AI tools present an opportunity for security operations teams. Investigating potential identity threats is a laborious task. However, well-designed AI agents with access to relevant identity logging can perform the time-consuming work of gathering rich context for analysts so they can make the most informed decisions possible about whether a login is benign or anomalous and suspicious or malicious.
SEE OUR IDENTITY DETECTION IN ACTION
Related Articles
Train, triage, repeat: The AI agent changing how we fight phishing
The dual-use dilemma: Rethinking detection for remote access tool abuse
The dual-use dilemma: Rethinking detection for remote access tool abuse
Investigating suspicious AI workflows in Microsoft Entra Agent ID: Assistive agents