
Incident response overview
In the context of cybersecurity, NIST defines an “incident” as any event that can potentially threaten the integrity, confidentiality, or availability of digital information or information systems. These incidents encompass a wide range of activities that violate security policies, acceptable use policies, or standard security practices.

Let’s consider a hypothetical anecdote to illustrate the concept of an incident. Imagine a mid-sized consulting firm that handles sensitive financial data for its clients. One day, an employee named Alex receives an email that appears to be from the company’s IT department, asking him to click on a link to update his password. The email looks legitimate, complete with the company logo and the IT department’s contact information. Unbeknownst to Alex, this email is actually a phishing message crafted by cybercriminals. Alex clicks on the link, which takes him to a website that mimics the company’s internal IT portal. He enters his current username and password, attempting to update his password as instructed. In reality, he has just handed over his login credentials to the attackers. With these credentials, the attackers gain unauthorized access to the company’s network, where they immediately seek out sensitive client information and financial data.
The intrusion is detected a few days later when an unusual pattern of data access triggers an alert in the company’s security monitoring system.
Types of security incidents
The above is just one example of the many types of incidents that your organization may face. Here is a non-exhaustive list of security incidents that could also occur in your environment. Bear in mind, none of these are mutually exclusive, highlighting the importance of a comprehensive security program—including an incident response plan.
- Phishing attacks: The practice of sending fraudulent communications that appear to come from a reputable source, usually via email, with the goal of stealing sensitive data like credit card numbers, login credentials, and identities.
- Security breach: Unauthorized access to data, applications, services, networks, or devices by bypassing their underlying security mechanisms.
- Malware infection: The introduction of malicious software designed to disrupt, damage, or gain unauthorized access to a computer system.
- Denial of service (DoS) attacks: Attempts to make a machine or network resource unavailable to its intended users, usually by temporarily interrupting, overloading, or suspending the services of a host connected to the internet.
- Data theft or loss: Unauthorized copying, transfer, or retrieval of data, which could be sensitive, proprietary, or personal information.
- Ransomware attacks: Delivering a type of malicious software designed to block access to a computer system or data—typically by encrypting it—until a sum of money is paid; in some cases, these operators will skip the ransom and go straight to extortion.
- Insider threats: Malicious threats to an organization that come from legitimate users such as current employees, former employees, contractors, or business associates, who have inside information concerning the organization’s security practices, data, and computer systems.
What is incident response?
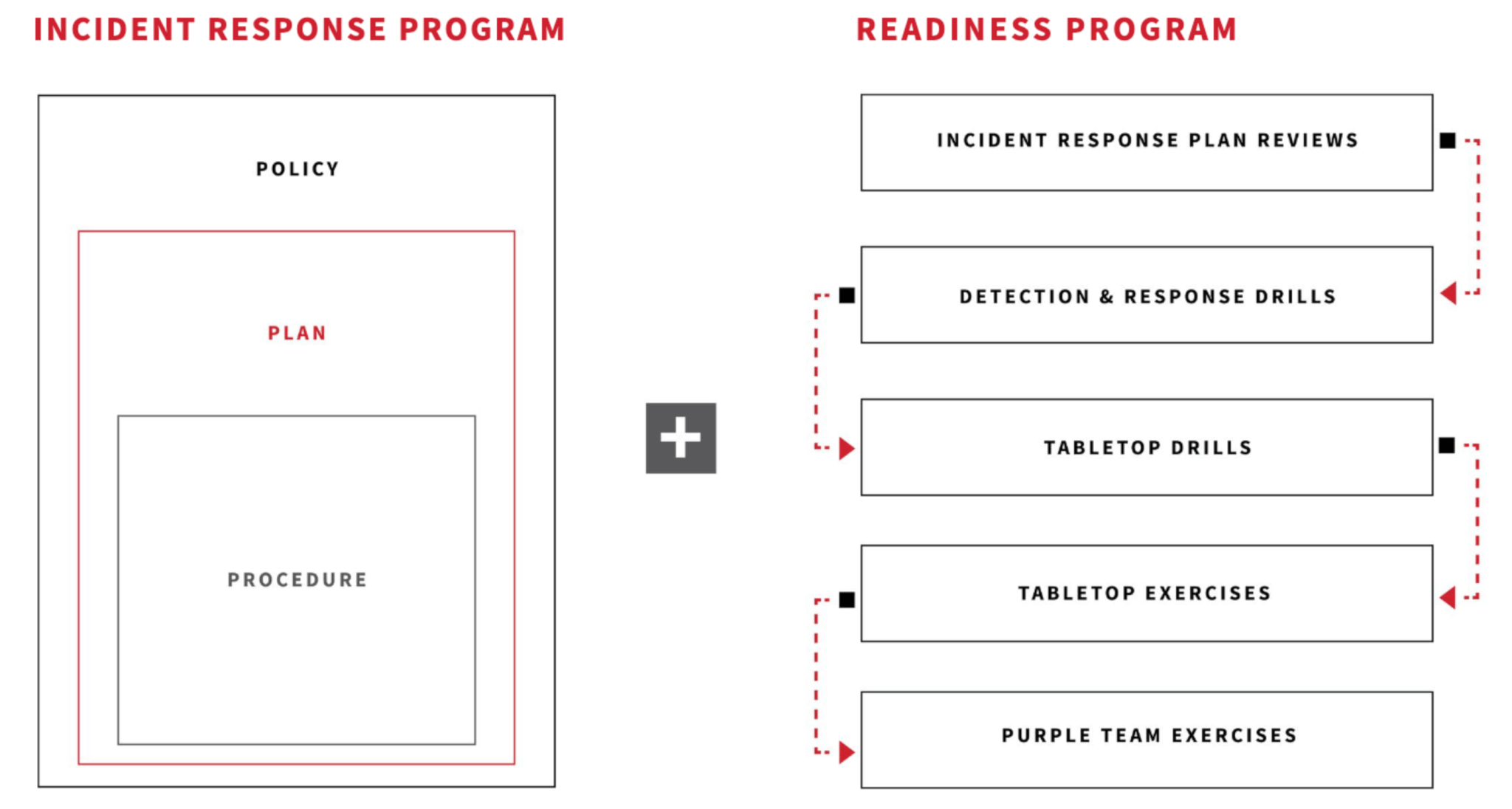
Before we explore why it’s important, let’s explore what it means. Incident response refers to the organized approach to developing, managing, and performing defensive actions, on behalf of an organization, once an incident has been identified. The goal of incident response is to handle these incidents in a way that minimizes damage, reduces recovery time and costs, and mitigates the risks associated with it. An effective incident response strategy should involve—at the very least—three core tenets: policy, plan, and procedure.
Policy
A policy is a high-level document that outlines an organization’s overall stance, principles, and directives for managing cybersecurity risk and responding to incidents. It sets the foundation for the incident response program by defining the scope, objectives, and responsibilities across the organization. A cybersecurity incident response policy typically includes:
- The organization’s commitment to managing cybersecurity risk
- Definitions of roles and responsibilities for incident response, including the formation of an incident response team
- The legal and regulatory requirements the organization must adhere to in the context of incident response
- Guidelines for internal and external communications during an incident
The policy serves as a framework within which more detailed plans and procedures can be developed, ensuring that all actions are aligned with the organization’s overall goals and compliance obligations.
Plan
A plan provides a detailed blueprint for how to detect, respond to, and recover from cybersecurity incidents. It is more specific than a policy and translates the high-level directives of the policy into actionable steps. While we will discuss incident response plans (IRP) more granularly later in this article, one typically includes:
- The specific procedures for detecting and reporting incidents
- The process for assessing and classifying the severity of incidents
- Detailed response strategies for different types of incidents (e.g., ransomware, data breach, DoS attack)
- Recovery plans to restore systems and operations to normal after an incident
- Exercises and drills to prepare the incident response team and other relevant staff
The plan is action-oriented and focuses on the “who,” “what,” “when,” and “how” of responding to an incident.
Procedure
Procedures are the most detailed and specific documents within the incident response program. They provide step-by-step instructions for carrying out the activities outlined in the incident response plan. Procedures are designed to be executed by the incident response team and other involved personnel, ensuring that actions are taken efficiently and consistently. They include:
- Detailed instructions for collecting and preserving evidence for forensic analysis or legal proceedings
- Specific technical steps for containing and eradicating a threat
- Checklists and workflows for responding to specific types of incidents
- Communication templates for notifying stakeholders and external parties
Procedures ensure that the tactical aspects of incident response are carried out effectively, minimizing the impact of incidents on the organization.
Incident response plans
The overall objective of an incident response plan (IRP), as mentioned above, is to develop a blueprint that ensures business continuity and safeguards sensitive information pertinent to your company and/or the customers it serves. It also acts as a guide for practitioners when it comes to handling incidents in real time. Creating or updating such a document often involves internal stakeholder collaboration (i.e., executives, security team, legal counsel, etc). With the SANS Incident Response Cycle, known by its acronym of PICERL, serving as the framework, the organizational steps below will enable you to prepare for and respond effectively to incidents while also serving as the primary tenets that shape the IRP.

Preparation
It is crucial to create a well-documented and well-communicated IRP that outlines the steps to be taken when a security incident occurs. The framework below serves as the fundamental guiding principles when it comes to developing an IRP. In addition to adopting such a plan, you’ll want to consider documenting the team of individuals tasked with specific roles and responsibilities (outlined by the incident response policy document) that are to be executed during incidents. A defined team is just as important—if not more so—to the outcome of an incident then the plan itself. Once a team is identified and a plan is in place, the final component of preparation is conducting training and drills at a repeatable, frequent cadence. Ensuring that the incident response team is adequately trained and that the IRP is regularly tested through simulated exercises is key to your security posture.
Identification
Being able to accurately identify suspicious and malicious activity is paramount when it comes to the response process. Otherwise, incidents would pass by unnoticed. The intricate nature of modern networks necessitates the collection of telemetry and events from diverse sources such as endpoints, networks, the cloud, and the web. Various tools are employed to detect different threats and generate alerts or notifications as needed. Security products may incorporate built-in detection logic or task security teams with creating customized detection analytics.
Certain detectors operate on signatures, relying on static indicators like IP addresses, binary hashes, and other forensic traces. Others adopt a behavioral approach, analyzing adversary actions such as unconventional process relationships, command-line parameters, or a combination of endpoint and network activities. While signatures excel at detecting known malicious patterns, they often have limited value as adversaries swiftly adapt their behavior to nullify existing detection methods by altering hashes or shifting to new domains.
Detecting behaviors is more intricate, demanding sophisticated tools and operational expertise. However, the investment is offset by the durability of behavioral analytics. Advanced security teams commonly rely on a blend of signature and behavior-based detections, often developed in-house with external assistance.
Whether it’s a threat on an endpoint, in the cloud, or elsewhere within your network, you need to know your network landscape in order to accurately identify the logs that need to be monitored for suspicious activity. Using resources like our annual Threat Detection Report for intelligence and actionable insights on the latest tactics, techniques, and procedures (TTP) is a good way to stay ahead of adversaries and provides blue teams with knowledge on where to look for suspicious and/or malicious activity.
Containment
This is the phase at which the response team initiates interaction with the affected hosts. The primary objective at this stage is to prevent adversaries or malicious software from causing additional damage to the already compromised network. Standard containment measures may involve actions such as isolating an endpoint or cloud-based application, deactivating an identity, blocking executables based on their hash, or preventing communications with a specific IP address.
Containment is a multifaceted aspect of the incident response process, requiring responders to carefully balance risks and operational considerations. Some key considerations include assessing the risk posed to customers and the organization, evaluating the business impact of taking a system offline, and considering whether isolating an endpoint might alert adversaries to our detection, potentially impeding further investigation.
This is the phase when you isolate and minimize the impact of the security incident to prevent further damage or unauthorized access. You’ll likely implement temporary measures to control the situation while preserving evidence for further analysis. This can happen in the form of temporary token revocation, blocking IP addresses or networks, isolating a device, etc.
Eradication
After a threat has been contained by the response team, it is imperative to completely eliminate it (and the root cause of the compromise) from the endpoint, network, and/or cloud. This process generally includes tasks such as removing malicious code, invalidating tokens associated with unauthorized access, rebuilding endpoints or cloud instances, and ultimately validating that the eradication steps were thoroughly and effectively executed. This is also when long-term solutions to eliminate vulnerabilities or weaknesses come into play. Depending on the incident, you may need to harden your perimeter by patching an exploited vulnerability.
Recovery
Once a threat has effectively been eliminated from the network, you’ll need to move to bring systems back to baseline. This often includes re-imaging and validating the affected machines. It also includes recovery of function: say the incident prompted you to part ways with a cloud provider or required extensive collaboration with an upstream vendor. Ultimately, restoration of function is what leads to the return to normal operations.
Lessons learned
This aspect of IR is often under-valued and overlooked. Shortly after the dust has settled following recovery, it is best practice for an IR team to conduct a post-incident analysis to better understand the root cause of the given incident and determine areas for improvement. Since this final phase is known to all stakeholders in advance—because it is part of the documented and coordinated IRP—all parties should be keeping notes throughout the entirety of incident response operations that will inspire the eventual lessons learned. Once gaps have been identified, processes can be modified and the incident response plan can be adjusted to improve the organization’s overall security posture.
Incident response (IR) in real life (IRL)
The way incident response operations unfold is unique to each company and the environments they are securing, but the overarching framework remains the same. Let’s revisit Alex’s phishing scenario described earlier. The security team’s response to the phishing incident and subsequent unauthorized access involves several critical steps organized using the framework laid out above. Here’s a more detailed breakdown of how they might respond:
Preparation: Ideally, before the incident, the team would have conducted regular training sessions for all employees, including how to recognize phishing emails. Although Alex fell for the phishing attempt, ongoing education is crucial for minimizing such risks. The team also has a well-documented incident response plan that outlines roles, responsibilities, and procedures for various types of incidents, including phishing.
Identification: The security monitoring system flags unusual data access patterns, which prompts an investigation. During their initial analysis, security analysts review logs and systems to confirm the breach and identify the entry point (Alex’s compromised credentials).
Containment: The team immediately disables Alex’s account to stop further unauthorized access. They also temporarily restrict access to sensitive systems to prevent data exfiltration. The security team then deploys additional monitoring tools to watch for further suspicious activities, ensuring the attacker can’t regain access through another vector.
Eradication: The team identifies and removes any backdoors or malware the attackers installed. They ensure that the attackers’ means of access are entirely eradicated from the system. All employees are required to change their passwords, with a strong emphasis on using complex, unique passwords.
Recovery: Systems are carefully brought back online, ensuring they are clean of any malicious code and that security patches are up-to-date. Post-recovery, the security team implements enhanced monitoring to detect any signs of persistence from the attackers or additional breaches.
Lessons learned: The team conducts a detailed review of the incident, documenting the timeline, what was effective, and areas for improvement. Based on the incident, the security team updates their training programs to include the latest tactics used by attackers, focusing on practical exercises and simulations. The incident might have even revealed weaknesses in existing security policies or the need for new ones, leading to updates to how sensitive information is accessed and how to respond to future incidents.
Communication and compliance reporting will likely run concurrently alongside the incident lifecycle, looking something like this:
Internal communication: Regular updates are provided to management and affected departments, maintaining transparency about what happened, the impact, and ongoing recovery efforts.
External communication: If client data was compromised, the team prepares a communication plan to inform affected parties, adhering to legal and regulatory requirements.
Compliance checks: The team reviews the incident in the context of regulatory requirements, ensuring all necessary reporting and compliance measures are taken.
Reporting: If required, the incident is reported to relevant authorities and stakeholders, following legal and industry-specific guidelines.
This structured approach ensures that incidents are managed effectively, minimizing damage, speeding recovery time and ultimately improving business resiliency.
Red Canary can help you prepare
Check out Red Canary’s Incident Response and Readiness Guide for more insight and resources as you put together or refine your organization’s incident response plan.