
It has been said (maybe only by me) that 2018 will go down as one of the most challenging years to make a decision about which endpoint-based security product to purchase. A market that was always crowded but did benefit from segmentation is now seeing that segmentation erode. The lines between Endpoint Detection and Response (EDR) and Endpoint Protection Platforms (EPP) in particular are increasingly blurry.
Within these large categories, we have use-cases for everything from application control and antivirus to threat hunting and incident response. These use-cases and others are present in marketing material for both EDR and EPP. Despite this, it’s nearly impossible to tell without a great deal of experience and investigative research how effective any product—regardless of its self-described product segment—is for a given use-case. However, one thing is true of the current set of products in this space: they either offer you great visibility or they offer you great protection. None currently offer both.

As our team continues to learn about, evaluate, measure, and attempt to communicate the efficacy of a very wide variety of endpoint-based security controls, we’ve found it much easier to focus conversations on just a few critical questions:
Do you care about visibility or do you care about protection?
Most of you will read this question and your answer will be “yes.” As it should be. You can and should care about both visibility and protection. You can find products that are great at either. You just can’t buy a product today that is great at both. So, you have to choose.
The gap between a great protection platform and one built for visibility will sound minor but is probably substantial, and by forcing yourself to prioritize, you can evaluate the features and functionality that matter the most. If visibility is your priority, then data is king and any protection features can be evaluated as wants and not needs. If protection is what you need, then visibility is helpful, but you should examine things like the policy engine, detection techniques, and tuning dials.
But $vendor says that they do both!
They’re probably not lying. Every one of the leading products can check the boxes for visibility and protection, but each has a clear strength. What we want is a clear set of questions that we can ask, or criteria that we can use, to make a well-informed determination.
The bad news is that objectively measuring protection features and functionality has eluded us for decades. The good news is that measurement of visibility and detection is much closer to achievable. And if we hold that there are no products that are top performers in both areas, then we can evaluate products for visibility-based use-cases and use this evaluation to segment the broader categories.
Do you understand the defensive telemetry that each product provides?
The glaring difference between protection and visibility products is the data that they provide. And it isn’t easy to understand what each product provides, where, and how. If visibility is your priority—again for use-cases such as threat hunting or incident response—a couple of questions that you’ll want to answer specific to this functionality include:
- What data-types does the agent leverage?
- What data-types does the agent ship off of the endpoint and collect centrally?
These two questions are usually sufficient to cut through the intentional simplicity of product marketing (to include sales pitches and slide decks), which is going to use very basic language like “our agent leverages hundreds of data-types” or “our agent records process, file, network, and other activity.”
And you’re probably already starting to piece together how complex a matrix one might be able to build based on the answers to these two questions alone. Fortunately, it’s our job to understand this at both very high, decision-making levels, as well as the very low level required to facilitate detection engineering. This is a representation that we refer to often to help us differentiate and group products:
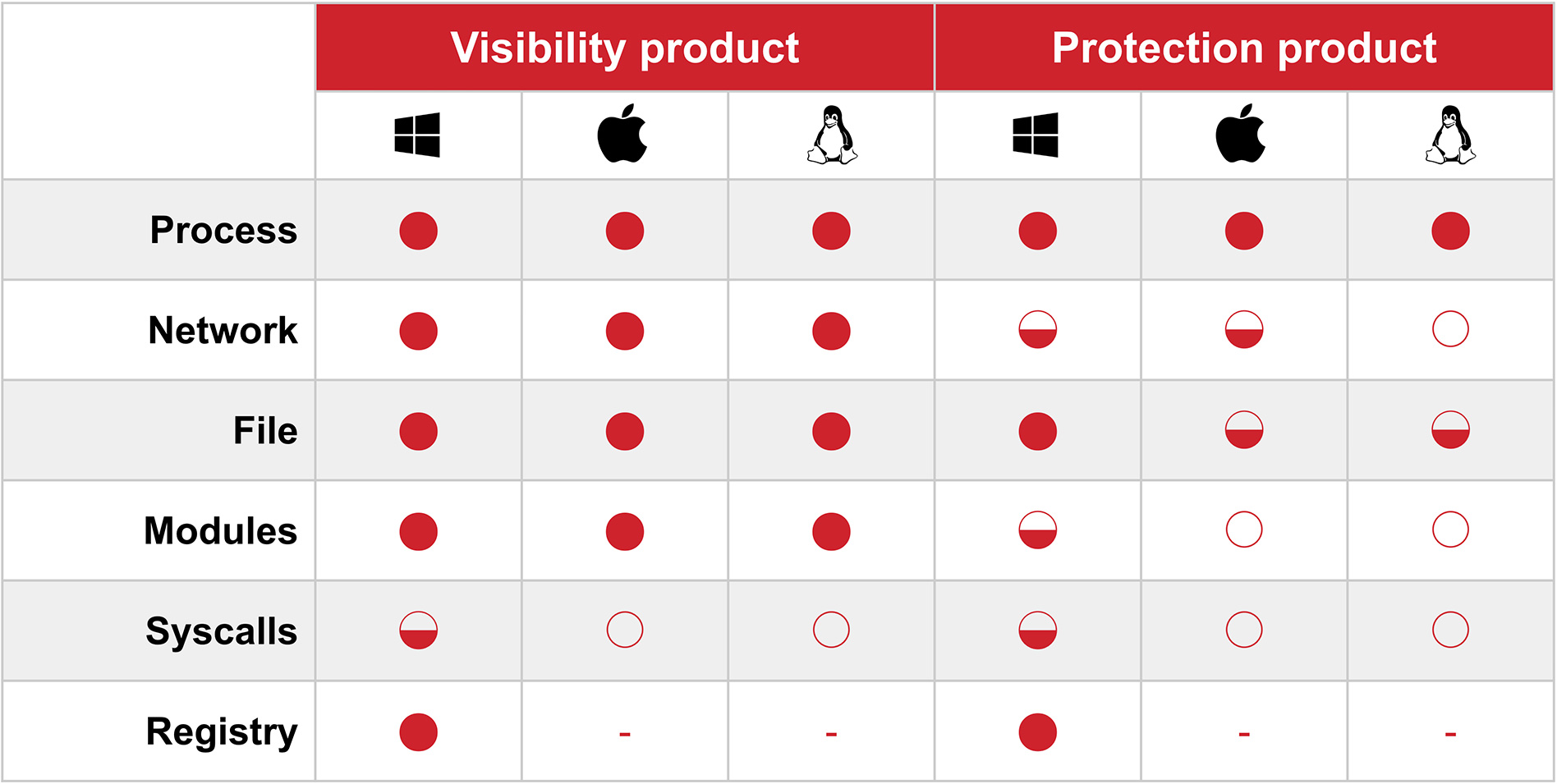
This matrix abstracts a number of specific products into two large groupings based on the type of data that they collect and the regularity with which that data is collected centrally.
- A full Harvey Ball indicates that the data type is always centrally collected
- A half-full ball indicates that it is selectively collected
- An empty ball indicates that the data type exists on a given platform but that the product never collects it centrally
Thus, you can see that process metadata—the attributes of which aren’t consistent across all products, but are close enough for our purposes—is collected and centrally recorded by all products that we evaluated. Beneath the process row, we can see clear differentiation between products that are visibility-first and those that are protection-first. This matrix necessarily hides some details. There are protection-first products where central collection differs slightly from this representation, but the differences are slight and the gap between any of them and a visibility-first product is still apparent.
Once you’ve driven this wedge, a few more strikes at the axe include questions related to local data storage:
- What data types are written to disk locally vs. inspected and discarded? Some products will collect all of the data that we expect for visibility purposes, but store it locally unless asked to ship it up by an operator. Some will only ship up additional events if the product itself deems a process “interesting.”
- How is data on the local disk stored or spooled? Some products will store for a fixed amount of time, while others will ring-buffer based on available/allocated disk space, etc.
And then some important questions about data that is centrally collected:
- How often is collected data shipped off of the endpoint to the collection point? Data on the endpoint is data at risk of being tampered with by an adversary.
- What is the format of collected data?
- How long is collected data stored on the server? Can this be adjusted—and at what cost?
- How can collected data be accessed or searched?
Do you know how to measure or objectively evaluate data collection?
If you don’t have visibility, use-cases related to investigation or coverage are moot. You can’t detect what you can’t see.
All of these questions about data collection are great. But they are aimed at understanding the mechanical aspects of collection, and they tell us little about the value of data for a given use-case. You are going to ask questions of your data for some reason, and thus it is critical that you understand what data you have and how it maps to questions that you can expect to ask.
MITRE ATT&CK™ has become the de facto standard for measurement, but I’d argue that we’re still not sure what we need to measure. The two most common use-cases for ATT&CK are:
- Measuring visibility
- Measuring detection coverage
For our purposes, we’ll look at how we can use ATT&CK to measure visibility.
ATT&CK provides data sources for each technique. These will be things like “process monitoring” and “process command-line.” If you know what types of questions you plan to ask of your data, these data sources can be helpful in determining which endpoint product you choose (or, whether your questions demand another product in addition or in place of the endpoint!). The full list of data sources is embedded in the following table:
| API monitoring | Detonation chamber | Named Pipes | System calls |
| Access Tokens | Digital Certificate Logs | Netflow/Enclave netflow | Third-party application logs |
| Anti-virus | Disk Forensics | Network device logs | User interface |
| Application Logs | EFI | Network intrusion detection system | VBR |
| Asset Management | Email gateway | Network protocol analysis | WMI Objects |
| Authentication logs | Environment variable | Packet capture | Web application firewall logs |
| BIOS | File monitoring | PowerShell logs | Web logs |
| Binary file metadata | Host network interface | Process Monitoring | Web proxy |
| Browser extensions | Kernel drivers | Process command-line parameters | Windows Error Reporting |
| Component Firmware | Loaded DLLs | Process use of network | Windows Registry |
| DLL monitoring | MBR | SSL/TLS inspection | Windows event logs |
| DNS records | Mail server | Sensor health and status | |
| Data loss prevention | Malware reverse engineering | Services |
An interesting first pass at understanding this is asking some questions of the data sources. You can use this simple utility or something more full-featured like the ATTACK-Python-Client maintained by Cyb3rWard0g and Cyb3rPanda.
As an example, we know that process metadata, to include the process command-line, are a very good place to start for both hunting and detection use-cases. But until recently, we had no idea whether this data set brought us observability into some or most ATT&CK techniques. Fortunately, the ATT&CK API allows us to ask these questions:

First, we seed a file with the two data sources common to most EDR and EPP products: process command-line parameters and process monitoring. Then we query the API to see how many techniques exist, and what subset of them we can observe using these data sources. 74 percent isn’t bad! A couple of caveats:
- Observability and detection are not the same thing.
- Detection and investigation are even farther removed.
These caveats aside, we now know that we can observe roughly 75 percent of known techniques using these data sources, which means that detection and investigation are possible. We also know that visibility-focused endpoint products can get us to 85 percent or more, and that we can close many of the remaining gaps with platform-native log collection (often using open source tools).
These observability metrics are specific to ATT&CK techniques, which are not representative of the additional questions that you should ask when hunting for anomalous activity or that you must ask when performing remote forensics and incident response. Again, for these use-cases, data is king.
Sidebar: Remember that detection is much broader than ATT&CK.
Do you understand the relative value of data for detection?
Once you understand what each product collects, how it maps to known adversary techniques, and also how it stacks up against the products that we know are enabling more visibility than others, it’s time to consider the value of each data source for your use-case(s).
Our Detection Engineering team maintains a corpus of well over a thousand detectors (detection criteria, written in a domain-specific language for our platform) that parse endpoint data. Because we’re performing investigation on events raised by these detectors, it’s difficult to say with certainty which data-sources are most valuable, but we can generalize. From most valuable to less valuable, generally:
- Process metadata
- Process command-line
- Process relationships (children, parents)
- Cross-process events (injection, remote thread operations)
- Binary attributes and metadata
- Binary trust
- File events
- Network events
- Everything else . . .
Again, these are primarily used for detection. For incident response use-cases, additional data-sources are invaluable. And referencing the data collection matrix above, a key differentiator is whether these events are collected always or selectively (i.e., only when the agent detects a suspicious event and sends more complete telemetry to a central collection point).
Conclusion
Hopefully this set of criteria and questions are valuable, particularly for anyone taking the difficult first pass at selecting an endpoint technology. By dividing the endpoint space into just these two broad categories, it can help to drive focus and prioritization. If you can determine whether you value visibility or protection, then you have achieved a very meaningful level of segmentation. You may also come to another conclusion entirely, which is that you value outcomes above all else. If that’s the case, then you may seek a partner to help you make your product choice based on the right mix of your technology requirements and the specific security outcomes that you seek.
Register to download our EDR buyer’s guide.
Related Articles
How AI will affect the malware ecosystem and what it means for defenders
How AI will affect the malware ecosystem and what it means for defenders
Why Taylor Swift fans should work in cybersecurity