
Editor’s note: This blog was written by a Red Canary detection engineer who uses the pseudonym “Han Shan.”
Who doesn’t love a website with a quirky, eye-catching top-level domain (TLD) like .ai, .io or .coffee?
Security practitioners, that’s who.
Yes, having a TLD that breaks the old .com conventions (comventions?) is both fun and useful. One could argue that it’s the modern equivalent of custom voicemail. But, not all TLDs are created equal and some are more practical than others for malicious use. In this article, we will discuss a researcher’s proof of concept for abusing Google’s .zip domain to accomplish some clever user deception. Then we will build further on that idea to uncover more techniques and, finally, lay out how to detect this behavior.
Background
In May 2023, Google released several new TLDs that can be purchased for use. Among them were .zip and .mov. These two stand out because they are also very common extensions for files that a user might want to legitimately download from the web. ZIP is a compressed file (and incredibly common in delivering malware, more on that later), and MOV is a video format developed by Apple for QuickTime software.
As a side note, the QuickTime framework has been deprecated for some time now, a fact that should make anyone who remembers the software feel old. This is important to know from a behavioral perspective because a user should rarely be downloading .mov files from the internet. ZIP files, though, are still incredibly common. The rest of this article will focus on .zip domains because of this environmental majority. The concepts we are about to discuss do not just apply to these new domains—they can be leveraged with any future TLD that might share a name with common file extensions.
While we have not seen much malicious use of the new .zip domain in the wild, security researchers have already demonstrated two primary ways that an adversary could abuse this domain to trick users. First is with a phishing site that appears to be a legitimate web page but includes .zip domain. This is a common phishing tactic with every TLD, so nothing new here.
A second attack method, which is much more insidious in terms of trickery, was demonstrated by @bobbyrsec in a terrific Medium writeup.
Unicode deception
In this writeup, @bobbyrsec presents two URLs that look almost identical. One downloads a ZIP file as intended by the user, and the other URL takes the user to a different website under an assumed attacker’s control, automatically downloading a malicious file. The only visual difference in the URLs is the presence of an @ symbol.

How does this work? As explained by @bobbyrsec and in this joint academic paper on URL parser implementations, if there is an @ symbol in a URL but no forward slashes anywhere before it (with the exception of http://, https://, or other schemes at the beginning) then most browsers will assume that any characters before the @ symbol are user information and will effectively ignore it, thus taking the user to whatever website is listed after the symbol. However, forward slashes are interpreted as directory paths on the server, so an @ symbol after any forward slashes will be read as part of a directory or filename.
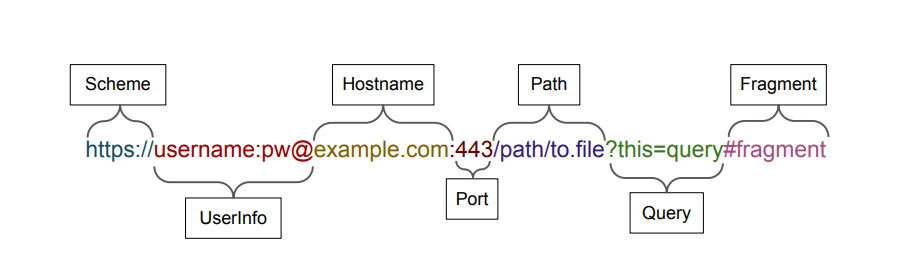
Image courtesy of jeyvrey.net
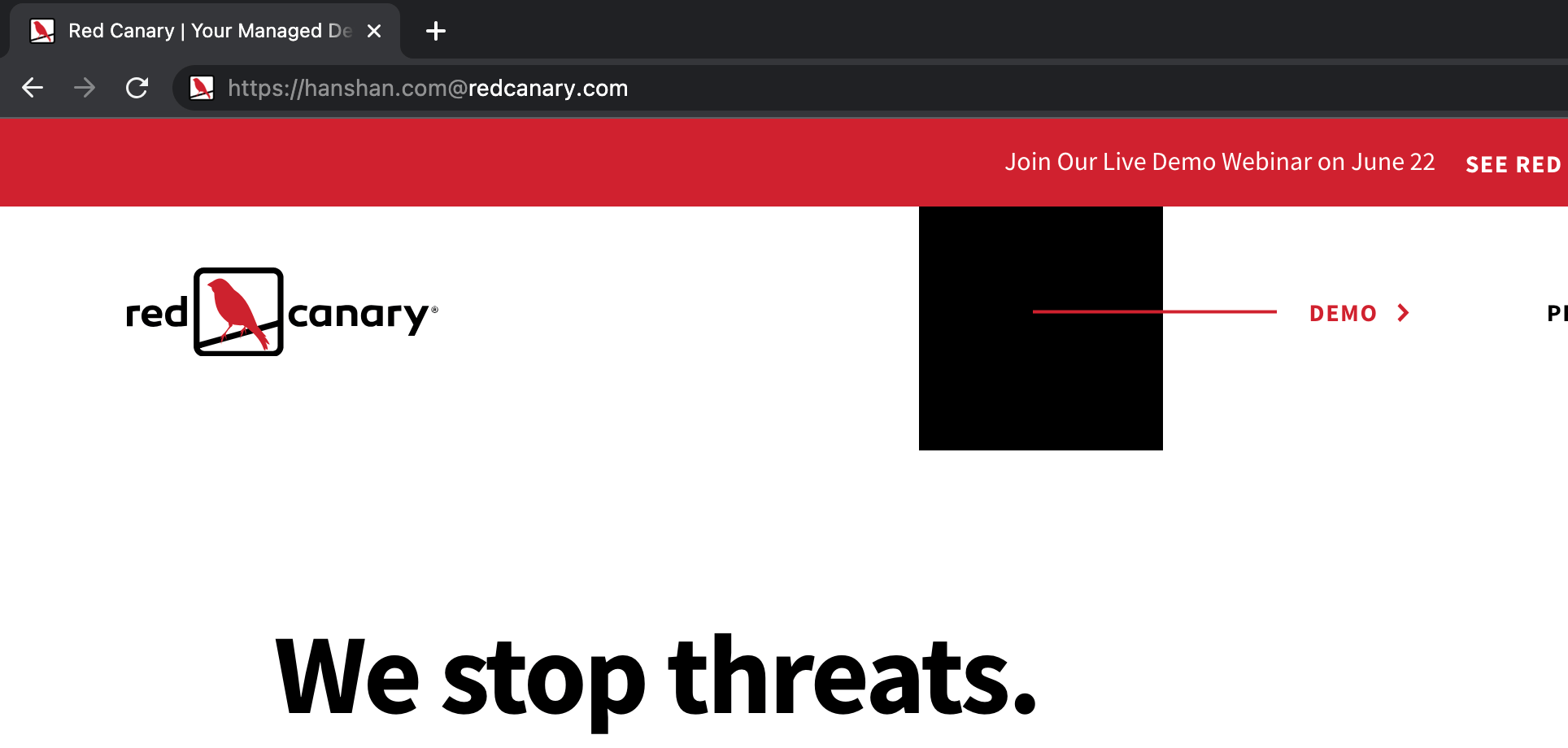
This is why the URL https://hanshan.com@redcanary.com will take you to Red Canary’s homepage. You can see in this screenshot that Chrome also grays out the portion of the URL before the @ symbol.
However, for the URL https://redcanary.com/path/to/file/@hanshan , Chrome will interpret the @ symbol as part of a directory or filename (which, in this case, does not exist).
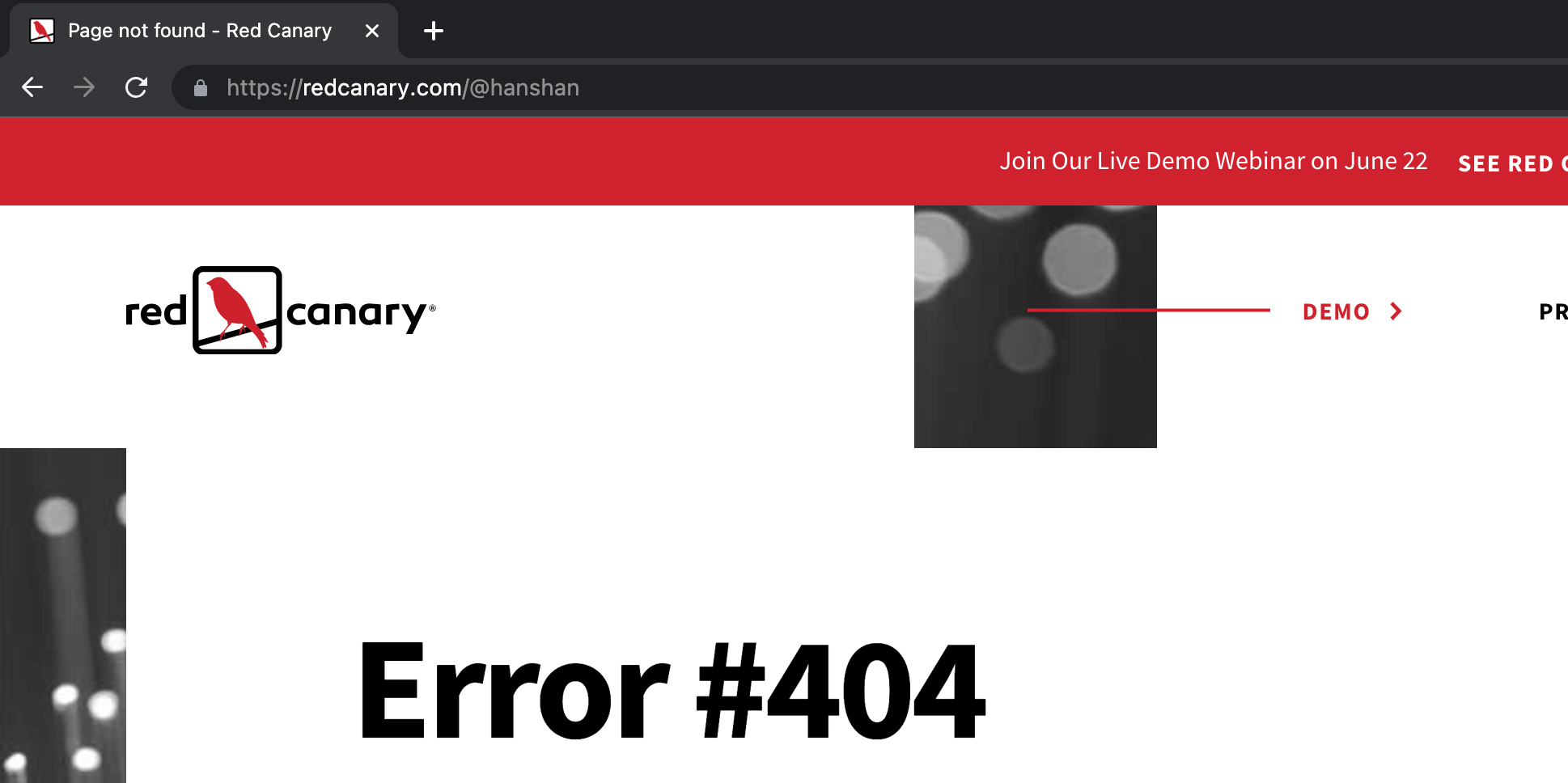
Therefore, if an @ symbol is used in a URL with no preceding forward slashes, then the browser will take the user to whatever is after the symbol.
But wait, there are forward slashes in both of the URLs demonstrated by @bobbyrsec. This is where unicode characters can add to the deception. An adversary can use U+2044 (⁄) and U+2215 (∕) in a URL to make the user think they are clicking a normal link, but the browser does not interpret those unicode slashes as actual slashes. So, companyname.com/resources/@this-is-not-a-file.zip with unicode slashes will take the user to the malicious domain this-is-not-a-file.zip.
A defender could tune their tools to detect unicode slashes in URLs and that would work against some malicious links, but let’s take this idea one step further.
Further deception
What if an adversary used this link instead?
https://companyname.com%20utm%7Eyawniatnuomdloc%7E.info@this-is-not-a-file.zip
Or, maybe this one:
https://companyname.com%20utm%7E5Ye655Sf5LiJ5Y2B5bm077yMIEnigJl2ZSBiZWVuIGluIHRoZSB3b3JsZCBmb3IgdGhpcnR5IHllYXJzLArnlbbpgYrljYPokKzph4zjgIIgQW5kIEkgbXVzdCBoYXZlIHRyYXZlbGVkIGEgbWlsbGlvbiBtaWxlcy4K6KGM5rGf6Z2S6I2J5ZCI77yMIFdhbGtlZCBieSByaXZlcnMgd2hlcmUgdGhlIGdyZWVuIGdyYXNzIGdyb3dzIHRoaWNrLArlhaXloZ7ntIXlobXotbfjgIIgQW5kIGVudGVyZWQgdGhlIGZyb250aWVyIHdoZXJlIHRoZSByZWQgZHVzdCByaXNlcy4K6Y2K6Jel56m65rGC5LuZ77yMIFB1cmlmaWVkIHBvdGlvbnMgaW4gdmFpbiBzZWFyY2ggZm9yIGltbW9ydGFsaXR5LAroroDmm7jlhbzoqaDlj7LjgIIgUmVhZCBib29rcyBhbmQgcGVydXNlZCB0aGUgaGlzdG9yaWVzLgrku4rml6Xmrbjlr5LlsbHvvIwgVG9kYXkgSSByZXR1cm4gdG8gQ29sZCBNb3VudGFpbiwK5p6V5rWB5YW85rSX6ICz44CCIFBpbGxvdyBteXNlbGYgb24gdGhlIGNyZWVrIGFuZCB3YXNoIG91dCBteSBlYXJzLg%7E%7E@this-is-not-a-file.zip
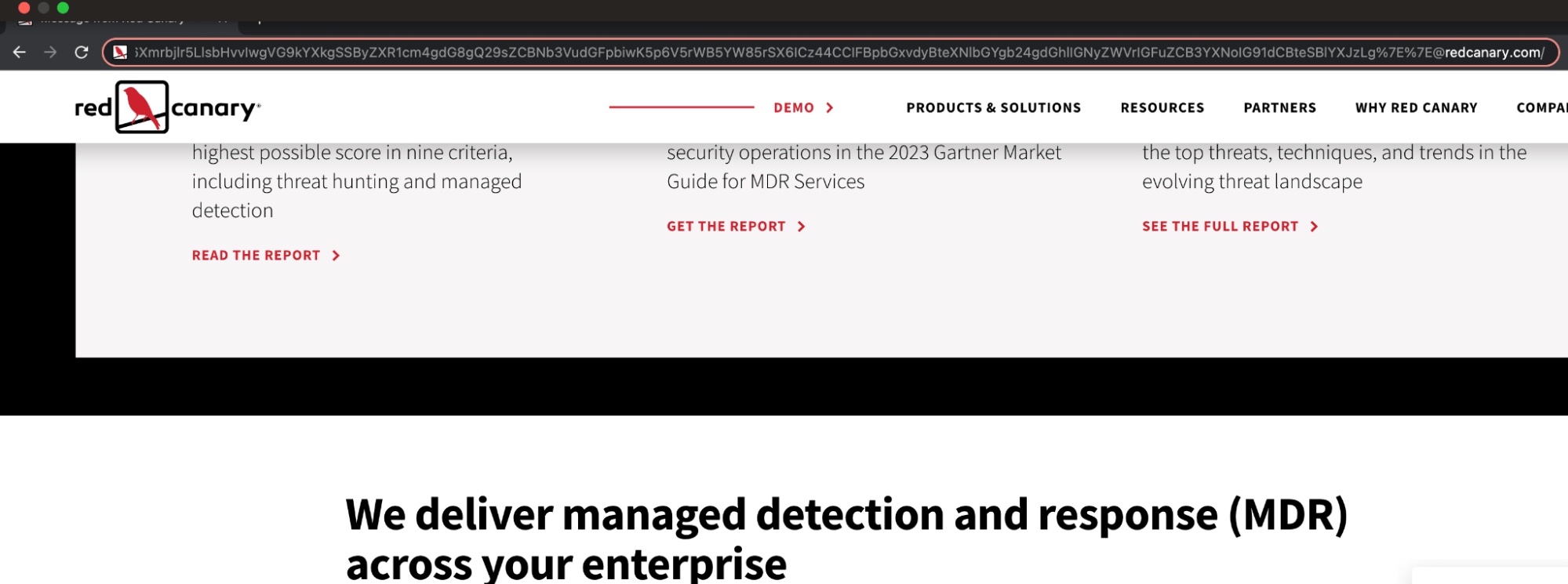
As you can see, the browser still ignores everything before the @ sign (to include a URL encoded forward slash: %2F) and takes the user to whatever domain it sees immediately after. In the case of the screenshots, it’s redcanary.com. But you could also use a .zip domain with a name that matches what the user is expecting to download.
How many of us have seen (or clicked on) confusingly long links like that? The URL encoding and Base64 string in those URLs are completely arbitrary. I only added them to make the link easier to glaze over so the user only pays attention to the beginning of the URL (a safe website name that they trust) and the .zip at the end, since they want to download a file from that safe website.
The scenario here is that the user receives this link in an email that says something to the tune of “Hey, the documents you wanted can be downloaded from our company SharePoint site. Here is a link to the ZIP file.” The user thinks they’re downloading a file from a safe web page (companyname.com) without realizing that they’re actually navigating to a different site entirely. Even if they pause to decode the Base 64, it’s just arbitrary gibberish (or perhaps an Easter egg from the adversary ). Long character strings show up in URLs all the time. There’s no indication to most users of anything malicious happening.
The user sees the messy link. If they think to hover over it to see where it takes them, all they see is this-is-not-a-file.zip. Maybe they question that, or maybe they just think, “cool, it’s going to give me the ZIP file, that’s what I want.”
These are some basic URL examples that we’ve experimented with internally. For further reading and other obfuscation examples, Mandiant has a good writeup on schema abuse and alternative hostname formats.
So what?
Why is this attack so clever? First, when the user navigates to https://companyname.com/resources/user/@this-is-not-a-file.zip (with Unicode slashes), or https://companyname.com%2futm%2fyawniatnuomdloc%7E.info@this-is-not-a-file.zip, odds are they are already planning to download a ZIP file. They are mentally framed and expecting their browser to download something from a place that they trust (companyname.com). Thus, it raises no red flags when the browser does exactly what the user expects.
Second, the only visual indicator is the @ symbol, which is pretty common in URLs. In fact, there’s one in the Medium link I posted earlier in this article. It would take a highly suspicious eye to pause and think about whether every @ symbol in every link they click on is part of a normal part of a server’s directory or file structure or if it’s there to trick the browser into navigating to a different site.
Detecting this technique
As stated before, a defender could look for unicode slashes in URLs, as that should be a rare occurrence. But an adversary does not have to use those fake slashes. The only requirements for the attacker is the @ sign, no problematic characters preceding it, and a tricky TLD (.zip).
Regex can come in handy here. This is a basic regex search pattern that can look for malicious URLs:
/https?:\/\/[^\/]*@[^\/]*\.zip$/
Here’s a breakdown:
https?:\/\/= looks for the schema (https://) literally with the trailingsoptional.[^\/]*= looks for any character that is not a literal forward slash, zero to unlimited times. This will cover Base 64, URL encoding, or other URL safe characters that an adversary may place between the schema and@sign. This should be rare if you are only detecting normal web activity, but may generate noise if your environment has some internal special use cases. If so, you can add other characters to exclude here.@= looks for the literal @ sign, indicating a that the browser is going to ignore everything preceding it and will look for a domain name after the sign (since we’ve checked that there are no forward slashes preceding it)[^\/]*= again looking for characters while excluding forward slashes\.zip$= the .zip TLD, anchored to the end of the URL
Conclusion
Niche TLDs can be a great way for a company to stand out from the .competition, but TLDs that match file extensions can be used by attackers to deceive users. Don’t get stuck on the zipper though—these techniques are applicable to any future problematic TLDs as well. It’s important to get ahead of the curve and develop detection techniques for potential abusive links should they ever become common attack methods.
Related Articles
Train, triage, repeat: The AI agent changing how we fight phishing
The dual-use dilemma: Rethinking detection for remote access tool abuse
The dual-use dilemma: Rethinking detection for remote access tool abuse
Investigating suspicious AI workflows in Microsoft Entra Agent ID: Assistive agents