
The SANS Institute recently published the results of its annual Endpoint Protection and Response survey through a report written by Lee Neely and advised by Alissa Torres. The report includes a number of statistics and a long list of takeaways, but the key findings it uncovered are:
- We have too many tools
- We have too many alerts
- Neither of these things is leading to better security outcomes
Let’s take a closer look at the findings and evaluate potential strategies that can be used to address the challenges organizations are experiencing.
Too many tools
“Automating endpoint detection and response solutions is the top priority for IT professionals…. [but] while respondent organizations were able to procure these types of newer technologies, they lacked the resources to implement them.” —Lee Neely, 2018 SANS Endpoint Protection and Response Survey
Ironically, a war chest of tools and services is too often an indicator of ineffectiveness. Very few teams have the vision, expertise, and time to operationalize dozens of products and vendors. And having only two of the three doesn’t count. Often, teams are overextended, meaning strategic plans rarely get prioritized above helping the business meet its core objectives.
Let’s start by looking at a traditional and very common security architecture:
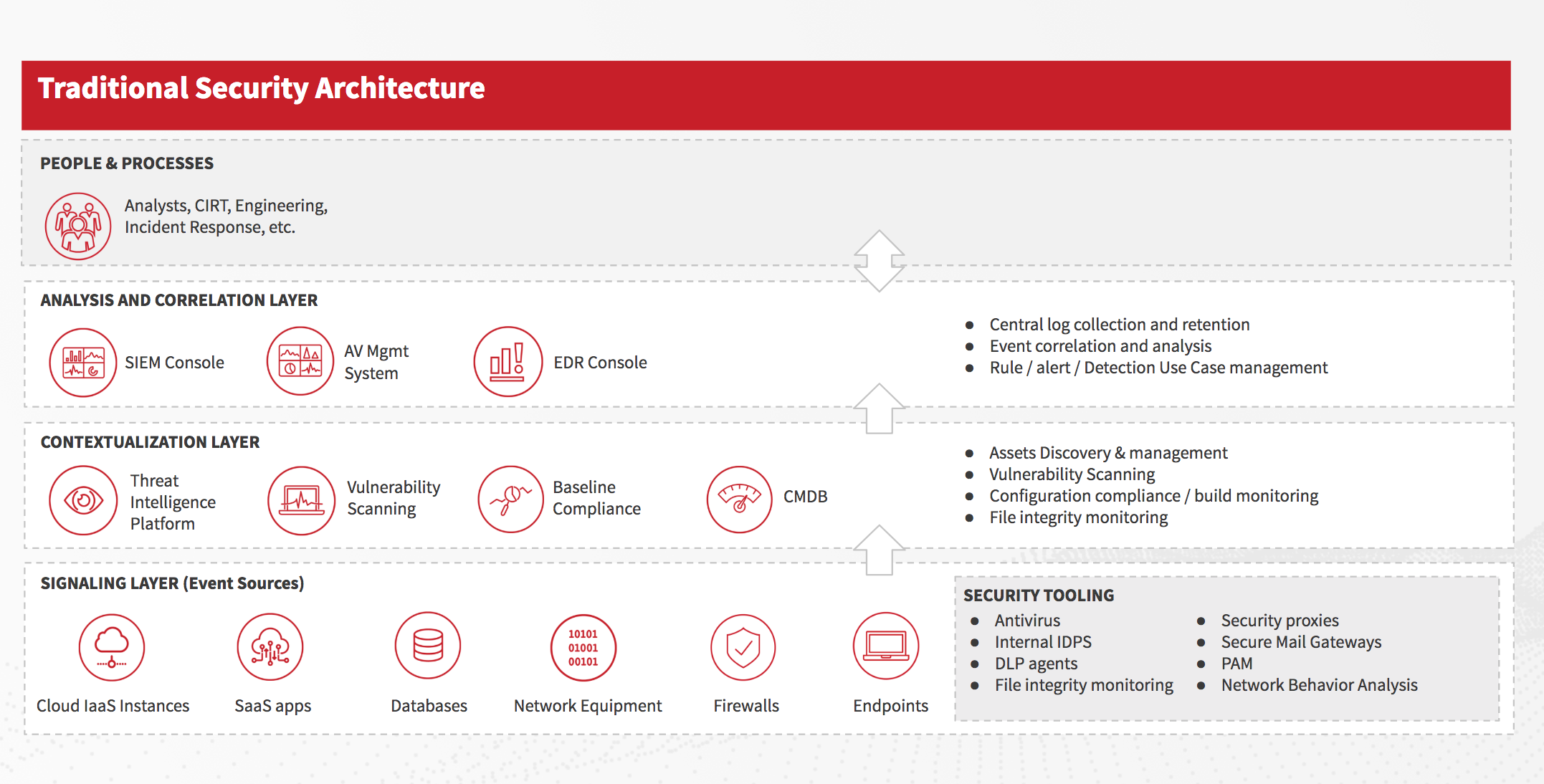
This seems like a big list of tools, and it is. With each addition to the toolbox, the team or its management anticipates that “this may be the one that gives us forward momentum again!” However, with too many tools and vendors to manage, the reality is that there’s more overhead to manage at the expense of actually integrating the new tool into the team’s processes.
It’s a classic “Catch-22” situation that leads to the next phenomenon pointed out in the study.
Too many alerts
Each of the systems above is generating some basic telemetry, sometimes in the form of informational alerts. Each is generating higher priority alerts that should be immediately actioned. Each has the ability to be tuned to look for organization-specific conditions beyond their canned alert criteria. Each has a management overhead with keeping the lights on, software updated, and best practices followed.
This all plays out in a very predictable manner:
- The team consumes alerts via email or an issue tracking system, and attempts to investigate them all until they can no longer keep up with the volume.
- The team looks to managed service providers (MSPs) to help with triage. Commodity service providers do not specialize, and are beholden to the myriad of data sources that their respective customers pay to submit. Thus, the MSP is only as good as it is managed and/or given feedback by the customer. So, some or all of the time supposedly saved by offloading triage is spent managing the relationship and performing investigations.
- The team looks to a SIEM as a means of bringing correlation and workflow closer to in-house. Everyone failed to mention that the only thing more time consuming than a fleet of controls coupled with an MSP is a SIEM implementation. This starts, but will never be finished.
- With more unfinished work than before, the team or its management starts to evaluate new tools that can help address the backlog. Stop me if you’ve heard this part before . . .
At no point does it occur to anyone that the team might do well to take a very different, albeit simple, approach: Willfully ignore some of the things that are causing the problem.
Improving outcomes
We keep referring to alerts, and it’s important to acknowledge the fact that alerts are only one part of a much larger security equation. The goal of your security team is not to be a more efficient alert processor. Your goal is to prevent bad things from happening as often as possible, and to minimize the impact of bad things when they do occur. Achieving this goal requires a specific process.
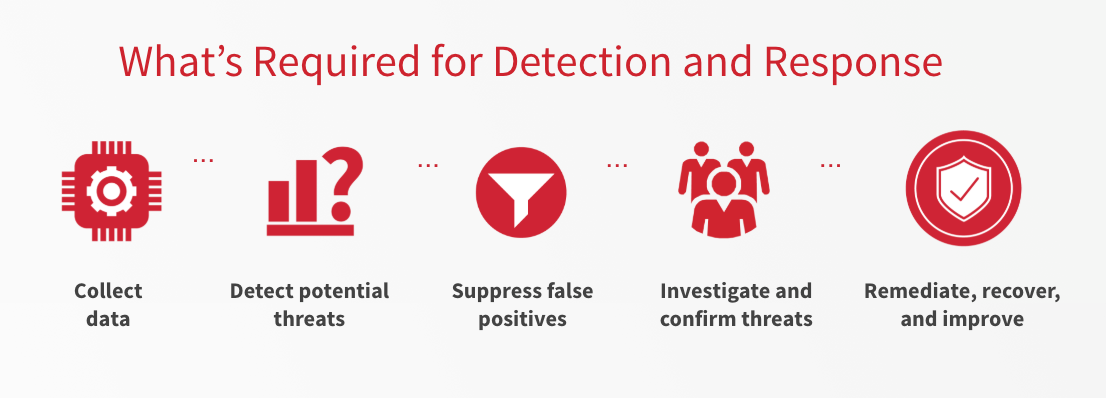 Your dashboards, telemetry, and alerts are only helpful if you can look meaningfully at them. Thus, your Cyber Incident Response Team (CIRT) or Security Operations Center must invest the time and effort to understand the data itself, how and when it is useful, and what questions to ask of the data to surface potential threats.
Your dashboards, telemetry, and alerts are only helpful if you can look meaningfully at them. Thus, your Cyber Incident Response Team (CIRT) or Security Operations Center must invest the time and effort to understand the data itself, how and when it is useful, and what questions to ask of the data to surface potential threats.
Your data is only as useful as you have time to ask it questions.
— Keith (@kwm) March 8, 2018
An alternative approach
So what can we do instead? The first step is to refer back to your architecture, identify data sources, and stack rank them based on their value. For the purpose of this exercise, the value of each data source can be looked at as a function of three things:
- Usefulness for detection (and prevention, defined as “detection with an action at the end”)
- Usefulness for response
- The team’s ability to operate it effectively (expertise + time)
Looking at the first two items in particular, you should ask, “When this system generates an alert, where do I have to go next?” In almost all cases, the answer is “the endpoint.” A network IDS alert may tell you what hit the wire. An antivirus alert may warn of malware. But where did these threats come from, and what else happened before and after they were detected? In both of these scenarios, the activity came from an endpoint that was running a process in the context of a user.
This is why we, and the respondents in this survey, look to systems such as Endpoint Detection and Response (EDR) that can be leveraged for detection, but can also provide most or all of the information and instrumentation needed to respond. A logical next step may be to fill remaining gaps by collecting high value log data from these endpoints, and then address device management and discovery gaps using network flow data.
Whatever your prioritized ranking may be, put detections from your highest-value data sources in front of your most valuable analytic asset: your people. Use log aggregation to capture everything that’s left.
The critical part of this strategy is understanding the difference between things that you are going to pour your time into learning, building detection atop of, and responding to when alerts are generated, and things that have value during a deeper investigation but that default to serving an enrichment role.
Put bluntly: Stop assuming that you need to write detection atop of every data source at your disposal.
Case Study: Proactive Discovery vs Reactive Alert Consumption
“Unfortunately, 32% of respondents reported that proactive discovery, involving active endpoint inquiry, detected compromises only 10% or less of the time, meaning that discovery is dependent on alerts from the endpoint or network tool…. Learning to discover attack behaviors rather than simple indicators of compromise is key to becoming proactive.” —Lee Neely, 2018 SANS Endpoint Protection and Response Survey
The concept of “proactive discovery” is a great one to drive this concept home with your team. In order to make the valuable shift from reactive alert consumption to proactive discovery, your team needs access to data, sufficient time to understand and work with the data, and a process for continuous hunting and operationalization.
For reference, Red Canary’s detection engineering process uses endpoint telemetry and works like this:
- Develop a hypothesis about an adversary’s tactics, techniques or procedures (TTPs)
- Profile normal behavior
- Craft detection criteria
- Test detection criteria
- Have a peer review the above
- Place the detection into production
- Re-evaluate its usefulness, deprecating when no longer needed
The checklist may vary, but having a checklist to document the processes your team will follow is a critical component. In our case, this checklist is executed every time we need a new piece of detection criteria. Looking at this in perspective, we have to execute this process at least once for every technique in the MITRE ATT&CK™ matrix. And in most cases, we have to execute it many times per technique to achieve a meaningful level of coverage.
As an example, we can look at the process Red Canary’s CIRT followed to detect application shimming. Application shimming is just one of 125 ATT&CK techniques, and ATT&CK techniques are not the only way to think about or implement detection. Yes, it’s a lot of work. As is the case with anytime you’re faced with a lot of work, the best way to get it it done is to prioritize the project, break it down into achievable milestones, and then make time to actually do it.
Key Takeaways
The 2018 SANS Endpoint Protection and Response Survey uncovered what many security teams have known for quite some time: investing in more tools does not necessarily result in better security. Teams that purchase tools to achieve control coverage, and then inundate themselves with alerts, are at a massive disadvantage over teams that can prioritize, operationalize, and ultimately master a much smaller number of systems and data.
Look at what you’re pouring in to the top of the funnel, prioritize based on value, segregate your data sources into those that you’ll pipeline directly to analysts and those that you’ll log, and then master the few while keeping the rest at arm’s length. Using this strategy, you can successfully operationalize endpoint or other valuable detection data sources, and at the same time help your team and your leadership better manage your portfolio, budget, and achieve better outcomes.
To learn more, watch an on-demand webinar: Opening the Floodgates: How to Analyze 30+ TB of Endpoint Data Without Drowning Your Security Team
Related Articles
How AI will affect the malware ecosystem and what it means for defenders
How AI will affect the malware ecosystem and what it means for defenders
Why Taylor Swift fans should work in cybersecurity