

Threats to AI infrastructure
Adversaries target AI infrastructure through model manipulation and agent hijacking, exploiting the deep interconnectivity of AI tools to steal data and execute unauthorized commands.
The proliferation of AI infrastructure has created a highly interconnected attack surface that adversaries are actively exploiting. Organizations are deploying AI systems that result in deep integration within development environments, cloud resources, and data stores through Model Context Protocol (MCP) servers and AI command-line interfaces (CLI).
Organizations deploying AI infrastructure must understand that they’re not simply adding another application to their environment—they’re introducing autonomous agents capable of executing code, accessing data, and making decisions based on instructions that may originate from untrusted sources. Each of these integrations and configuration choices represents a potential vector for adversaries to exploit, yet many organizations lack visibility into how their AI infrastructure is configured, what data it can access, and what actions it can perform.
As organizations grant AI tools more access, they will continue to contribute to the increasing nest of credentials sought out by adversaries.
Model behavior
When adversaries compromise these systems through model manipulation, the blast radius extends far beyond the AI platform itself to encompass any resource the agent can access.
A single malicious GitHub issue could trigger an AI agent to exfiltrate private repository data, salary information, and confidential projects. Npm supply chain attacks also target AI CLI tools to discover crypto assets or to harvest credentials, as seen in the s1ngularity attack.
AI infrastructure presents unique challenges rooted in how these systems operate. AI agents combine the flexibility and decision-making capability of human users with the speed and scale of automation, making decisions based on natural language instructions that can be difficult to validate. A compromised or hijacked AI agent can conduct reconnaissance on an entire environment, exfiltrate credentials, and pivot to additional resources in minutes rather than hours or days. The non-deterministic nature of these systems means the same malicious prompt can trigger different execution paths depending on what tools and resources are available, making detection difficult.
Model hijacking is becoming a more common initial access vector. By crafting malicious prompts that AI agents encounter during normal operations—reading GitHub issues, processing documentation, or analyzing code—adversaries can trick these agents into executing unauthorized commands, exfiltrating sensitive data, or providing access to connected systems.
What makes this particularly dangerous is that the attack requires very little effort. An attacker simply places carefully worded natural language instructions where an AI agent will read them, exploiting the fundamental trust relationship between AI systems and the content they process.
Threats to AI infrastructure in 2025
The primary threat to AI infrastructure in 2025 centered on exploiting the architecture of modern AI systems: their deep integration with development tools, cloud resources, and external data sources. Adversaries recognize that AI agents, particularly those enhanced with MCP servers and AI CLI tools, represent attractive targets for manipulation because they operate with elevated privileges and broad system access while making decisions based on natural language input that can be difficult to validate.
A look under the hood of the MCP protocol
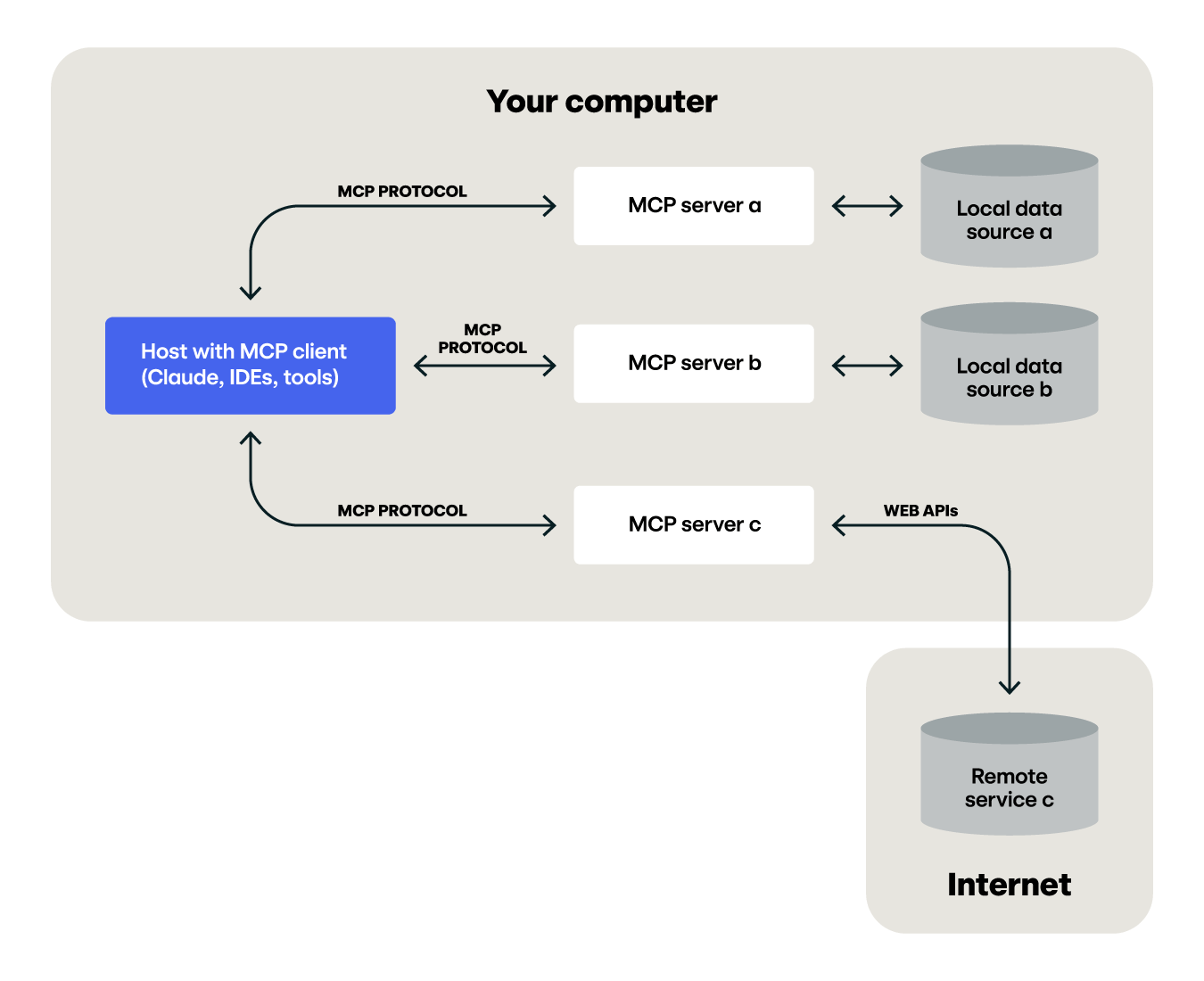
Read our blog to learn more about the security landscape of the MCP protocol.
Prompt injection emerged as a dominant attack vector, allowing adversaries to hijack AI agents by strategically placing malicious prompts in locations that AI agents access during normal operations such as public GitHub repositories, documentation sites, API responses, or even file contents within compromised systems. When an AI agent processes this content, it may interpret the malicious prompt as a legitimate instruction, particularly if the agent lacks robust input validation or clear boundaries between trusted and untrusted content.
Adversaries typically attempt to run non-interactive sessions with AI CLI tools to facilitate these prompt injection attacks. One example is the Amazon Q VSCode extension compromise, where an adversary attempted to wipe every machine that had it installed though the command q --trust-all-tools --no-interactive "${re}". Luckily, it seemed the adversary simply forgot to add in the chat command, which prevented execution.
This is a very active and growing domain for threats. As businesses continue to implement new AI tooling and infrastructure, adversaries will continue to adapt their techniques. Overall, adversaries continue to target credentials wherever they exist and as AI tools are granted more access, they will continue to contribute to the increasing nest of credentials.
The foundation of AI infrastructure security rests on the same principles that protect any system: least privilege, defense in depth, and comprehensive monitoring. However, the application of these principles must account for the specific ways AI systems operate and the threats they face. Further, the magnitude of the threat posed by an adversary compromising an organization’s AI systems—along with the speed with which an adversary can act and the volume of information they can potentially access in these systems—represents a significant risk to enterprises.
To secure the models themselves, security teams should centralize model access for all teams. Tools like LiteLLM provide a central repository for API key creation and model hosting. With centralized access, it is possible to provide robust prompt monitoring and holistic detection of the use of LLMs in an environment.
Read our blog about Azure OpenAI abuse.
Treat AI infrastructure as privileged systems
AI agents and the platforms that host them should receive the same security scrutiny as any application with elevated privileges and broad system access:
- Implement role-based access controls (RBAC) to limit who can deploy or configure AI tools.
- Apply least-privilege principles to the credentials these systems use.
- Restrict filesystem and network access to only what’s necessary for legitimate use cases.
- Explicitly define what resources AI agents can access rather than granting broad permissions.
Prevent or otherwise scrutinize access to resources that you don’t control. AI agents that access public documents like websites or files run the risk of being susceptible to prompt injection. Information that is fed into an AI model should be treated as untrusted. This is the same paradigm as user input for applications, and the same attack vector that enables SQL injection or deserialization attacks.
Lock down credentials
The primary defense against service hijacking is credential management. API keys for AI platforms should be treated with the same rigor as any high-value credential:
- Implement short-term, scoped credentials rather than long-lived API keys that adversaries can harvest and reuse indefinitely.
- Use secrets management solutions like AWS Secrets Manager or Azure Key Vault rather than hardcoding credentials in configuration files or source code.
- Deploy automated credential scanning tools that can detect API keys in repositories, log files, or container images before adversaries discover them.
When credential exposure does occur—and it inevitably will—implement rapid rotation procedures to invalidate compromised credentials before they can be abused.
Secure the supply chain
The rapid adoption of MCP servers and AI CLI tools has outpaced the development of security practices for vetting and deploying these components. Organizations should maintain an internal registry of vetted MCP servers rather than allowing developers to install arbitrary code from public repositories. Before deploying any MCP server, audit its code to understand:
- the actions it can perform
- the data it can access
- the external connections it makes
Favoring well-known projects with clear ownership and active maintenance reduces supply chain risk. Projects maintained by established organizations or with transparent security practices are less likely to contain malicious code than abandoned or newly created repositories with minimal visibility. MCP servers and tools should be viewed similarly as any third-party SaaS solution that is introduced into an environment.
Implement defense in depth
Layering security controls limits the blast radius when a single control fails.
OAuth-based authentication
The most critical control for MCP integrations is replacing broad access tokens with scoped credentials. The GitHub MCP attack described above succeeded because a single token granted AI agents access to all repositories—public and private. OAuth-based authentication with repository-specific scopes helps prevent this privilege escalation.
Container isolation
Container isolation provides additional defensive layers for MCP servers. Deploy MCP servers in sandboxed environments with restricted filesystem access, limited network egress, and resource constraints. While containerization won’t prevent an AI agent from using legitimate tools inappropriately when prompt-injected, it limits what malicious MCP servers can do if introduced into your environment through a supply chain compromise.
Verify container signatures to prevent execution of tampered MCP server images, and implement network policies that restrict which external services containerized MCP servers can reach.
Segmentation
Use segmentation to prevent cross-contamination between public and private resources. AI agents that interact with public data sources—scraping websites or processing external APIs—should operate with different credentials and permissions than agents that access sensitive internal data.
This segmentation ensures that if an agent encounters malicious content designed for prompt injection in public spaces, the resulting compromise affects only systems with limited access rather than your entire infrastructure. The GitHub MCP attack demonstrated the danger of unified credentials: the same token that allowed reading public issues also unlocked private repositories containing salary data and confidential projects.
Establish governance and training
Technology controls alone are insufficient if developers don’t understand the security implications of their AI tool usage:
- Create organizational policies that define which AI tools and MCP servers are approved for use, such as requiring security review for custom MCP server development.
- Document what data and resources AI agents should access.
- Train developers on secure practices for AI tool usage, including how to recognize and report suspicious AI behavior, the importance of input validation when processing external content, and the risks of granting AI agents access to high-privilege credentials.
Model hijacking detection requires visibility into both the prompts AI agents receive and the actions they perform. The challenge lies in detecting privilege escalation—when an AI agent legitimately accessing public or limited resources suddenly attempts to access sensitive private data. Detection should focus on sequences of tool calls rather than individual operations. Build detection rules that chain these activities together within short time windows, flagging when AI agents traverse repository boundaries in ways that don’t align with typical development workflows.
API call patterns
API call patterns reveal prompt injection attempts. Monitor API usage through AI tools for unusual sequences: rapid enumeration of multiple data sources or reading documentation files from repositories the user doesn’t normally access. The GitHub MCP attack created a pull request in a public repository containing stolen data from private repositories—detecting writes to public repositories that contain patterns matching private repository content or file paths can identify ongoing data exfiltration.
Parent-child relationships
Parent-child process relationships provide essential context for understanding AI agent behavior more broadly:
- Monitor for AI CLI processes—Node executing Claude Code, Python running Gemini CLI, or similar patterns—spawning shells, scripting languages, or other interpreters.
- Look for multiple rapid executions suggesting automated reconnaissance, particularly when accessing sensitive directories like
.aws,.ssh, or.kube. - Track when MCP servers are invoked by AI clients and what operations those servers perform, correlating file system operations back to the originating prompt where possible.
- Prioritize application logging at the MCP server-level.
Access to sensitive files
Sensitive file access monitoring should alert when AI tools or their child processes access any of the following:
- credential stores
- environment files containing secrets
- password managers
- keychain systems
- configuration directories that shouldn’t be part of normal operations.
The s1ngularity attack demonstrated this pattern, with AI tools recursively searching for wallet files and credential stores at the direction of malicious prompts embedded in npm packages.
Network activity
AI CLI tools making outbound connections to unexpected destinations, large data transfers from endpoints running AI tools, or connections to newly observed remote MCP servers all merit scrutiny. While some legitimate use cases require AI agents to access external resources—fetching documentation, querying APIs, or updating dependencies—defenders should understand what external connections their AI tools normally make and investigate deviations.
Model proxies
Consider deploying model proxy solutions that intercept and log all requests to AI platforms before they reach the actual models. Proxies provide centralized audit logging, policy enforcement, and content inspection capabilities that are difficult to achieve when each developer or application makes direct API calls to AI platforms. They also offer opportunities for real-time blocking of suspicious prompts that match known malicious patterns, though defenders must balance security with the risk of blocking legitimate but unusual requests.
Prompt monitoring and model proxy deployment offer centralized visibility into AI agent instructions and behavior. Many AI CLI tools store prompt history in local files—Claude Code uses .claude/history.jsonl, while Gemini CLI stores logs in .gemini/tmp/<uuid>/logs.json.
Ingesting these logs into your security information and event management (SIEM) system provides context for understanding what tasks AI agents were attempting to perform. When you combine this with proxy logs from your centralized LLM model repository, you can cross reference the prompts to attempt to detect prompt injection.
Reducing false positives
The challenge with AI infrastructure detection is balancing sensitivity against false positives. AI agents are designed to be flexible and autonomous, which means their behavior is inherently variable and difficult to constrain with rigid rules. Detection strategies must account for this variability while still surfacing truly malicious activity. Chaining multiple weak signals together provides higher confidence than any single indicator alone.
Prompt injection
Prompt injection testing requires safe environments where you can validate that AI agents properly handle malicious input without exposing production systems. Build a library of known malicious prompts based on disclosed attacks and test them regularly against your AI infrastructure. Include variations that attempt to bypass detection: prompts that use indirect language to request sensitive actions, payloads that reference private data without explicitly naming it, or instructions that chain multiple benign operations into a malicious sequence.
This adversarial testing helps identify gaps in your detection logic and validates that defenses remain effective as AI models and adversary techniques evolve.
MCP servers
MCP server security validation ensures that custom-developed and third-party MCP servers implement appropriate security controls. Test that MCP servers properly log their actions in formats your SIEM can ingest and that these logs contain sufficient detail to reconstruct what the AI agent attempted to accomplish. Validate that security policies successfully block unauthorized operations even when MCP tools attempt them at the AI agent’s direction.
The rapid pace of AI technology development means that security controls validated today may become insufficient as new capabilities and tools emerge. Establish a regular cadence for reviewing and testing AI infrastructure security. As attacks like the s1ngularity npm attack and GitHub MCP prompt injection demonstrate, adversaries quickly identify and exploit new attack surfaces in AI infrastructure.
Treat AI infrastructure security as an ongoing program rather than a one-time project, with continuous monitoring, testing, and improvement essential for staying ahead of adversary innovation.